Información general

Descripción
La arquitectura de referencia en datos es un marco estructurado que organiza, integra y protege la información, asegurando su calidad, disponibilidad y adaptabilidad para facilitar su acceso, análisis y aprovechamiento, impulsando la eficiencia operativa y la innovación tecnológica.
Objetivos, características y beneficios
Los objetivos esenciales de la arquitectura de datos son los siguientes:
- Integrar datos de diversas fuentes
- Garantizar la consistencia y calidad de la información
- Mejorar la eficiencia operativa
- Facilitar la toma de decisiones informada asegurando la disponibilidad y precisión de los datos.
- Promover la adaptabilidad, permitiendo una evolución gradual en respuesta a cambios en las necesidades funcionales y tecnológicas.
A continuación, se describen las principales características de la arquitectura de datos:
- Eficiencia en la gestión de datos, optimizando procesos desde la recolección hasta el acceso y análisis de la información.
- Calidad, integridad y consistencia de los datos. Establece estándares y procesos que aseguren estos aspectos.
- Seguridad y cumplimiento normativo, protegiendo la información sensible y garantizando el cumplimiento de regulaciones y políticas de privacidad.
- Fomenta la innovación al facilitar la adopción de nuevas tecnologías y la incorporación de enfoques emergentes, promoviendo la colaboración y la compartición efectiva de datos entre diferentes áreas de la organización.
La implementación de una arquitectura de datos robusta conlleva diversos beneficios que contribuyen a la eficiencia y el éxito operativo de una organización.
- Posibilita una toma de decisiones más informada al proporcionar acceso a datos precisos y actualizados.
- la eficiencia operativa se ve optimizada, ya que la arquitectura de datos define procesos estándar para la gestión y manipulación de la información, reduciendo el tiempo necesario para llevar a cabo tareas relacionadas con los datos. Este enfoque eficiente no solo ahorra tiempo, sino que también aumenta la productividad del personal al minimizar la carga de trabajo manual mediante la automatización de procesos.
- Flexibilidad y adaptabilidad. Permite a la organización adaptarse a cambios en los requisitos de datos y aprovechar tecnologías emergentes, asegurando que la infraestructura de datos evolucione con el tiempo y permanezca relevante.
- integración de datos, facilitando la unificación de información proveniente de diversas fuentes. Esto contribuye a una visión más completa y coherente de los datos, mejorando la comprensión global de la información.
- En términos de gestión de recursos, la arquitectura de datos optimiza la utilización de estos, al organizar y utilizar la información de manera efectiva. Evita redundancias y mal uso de datos, garantizando una asignación eficiente de recursos.
- Fomenta la colaboración entre diferentes departamentos al proporcionar un marco común para el acceso y uso de datos. Este enfoque cohesionador promueve un ambiente organizacional colaborativo y alinea a los equipos hacia objetivos comunes.
Principios
Partiendo de los principios generales definidos en la arquitectura global de contexto y que aplican en su totalidad a la arquitectura de datos, se definen un conjunto de principios específicos que se listan a continuación:
- Gobierno del dato
- Linaje del dato
- Integración e interoperabilidad
- Privacidad
- Curación de los datos
(*) Puede consultarse el listado de Principios Tecnológicos Generales.
Gobierno del dato
Establecer un marco de gobierno de datos que defina roles, responsabilidades y procesos para garantizar la calidad, la integridad y la seguridad de los datos. Estrechamente relacionado con los estándares y normas rigen los datos independientemente de su origen, tipo o volumetría. Ofrece una estructura organizativa que permite a los usuarios conocer la ubicación de los datos, así como su formato y propiedades, y la relación entre los mismos, y cómo se usan, permitiendo evitar problemas con la calidad de la información.
Linaje del dato
El linaje del dato rastrea los datos a lo largo de todo su procesamiento desde la fuente original. Conocer la procedencia de los datos es una necesidad relacionada con la auditoría, ya que si no se puede demostrar de dónde se obtuvieron los datos, dejarán de ser datos de confianza para las aplicaciones e informes. Asimismo, se deberá registrar cuándo han sido modificados y por quién durante el trascurso completo desde su obtención hasta su procesamiento, de forma que los usuarios puedan realizar una auditoría completa para garantizar la confiabilidad de los datos.
Integración e interoperabilidad
Diseñar sistemas que faciliten la integración de datos y fomenten la interoperabilidad, permitiendo un flujo eficiente de información. Se deberán interconectar e integrar los distintos sistemas donde residan los datos, permitiendo que se puedan combinar de las distintas fuentes, ofreciendo múltiples interfaces de acceso a los distintos usuarios para compartir la información. Dichas interfaces deberán depender del perfil del usuario que las use: por ejemplo, un usuario con perfil de BI utilizará una interfaz OLAP, mientras que un desarrollador o analista utilizará una interfaz SQL.
Privacidad
Incorporar medidas de seguridad y privacidad para proteger los datos sensibles y garantizar el cumplimiento de regulaciones y políticas. Se deben requerir políticas estrictas de seguridad y control de acceso a los datos, debiendo utilizarse herramientas para diseñar las capas de seguridad necesarias para proteger los datos debidamente, pero permitiendo un acceso automático a los usuarios que lo requieran.
Los datos personales de los usuarios deberán estar cifrados para mantenerse privados en el sistema. Esto conlleva el uso de cifrado en todo el ciclo de vida del dato (desde el origen, ingesta, almacenamiento y procesamiento), utilizando los siguientes métodos de cifrado:
- Datos en tránsito: en las comunicaciones entre sistemas, como la ingesta de datos desde fuentes orígenes, se deberá realizar mediante HTTPS utilizando certificados TLS.
- Datos en reposo: una vez los datos están en nuestro sistema (datalake, data warehouse), deberán estar debidamente cifrados mediante claves simétricas (i.e. AES) o asimétricas (i.e. par de claves pública/privada RSA) para que, ante un acceso no deseado, los datos no se vean comprometidos.
Curación de los datos
Se deberá ofrecer un sistema de curado de los datos para identificar, seleccionar, verificar, transformar los datos en dicho camino, de modo que facilite el mantenimiento por parte de los administradores del sistema y el uso en la capa de presentación y consumo, a la vez que se optimiza el uso y análisis.
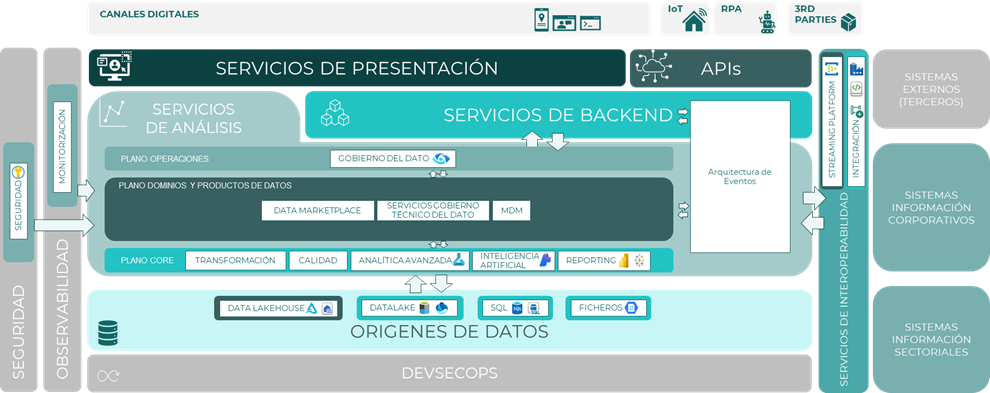
Componentes
Para la correcta implantación de una arquitectura de datos se debe contar con los siguientes componentes:
- Plano core
- Integración
- Transformación
- Calidad
- Datalake
- Analítica avanzada
- Reporting
- Plano dominios y productos de datos
- Data lakehouse
- Streaming platform
- Data Marketplace
- Servicios gobierno técnico del dato
- MDM
- Plano de operaciones
- Seguridad
- Monitorización
- Gobierno del dato
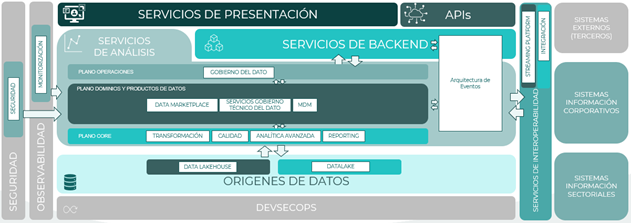
Plano core
Esta capa constituye los elementos de infraestructura y arquitectura que permiten a los dominios implementar sus sistemas. Dicho catálogo será testado, revisado, homologado y certificado para asegurar que cumple con las normas y estándares de la ADA. Se agruparán los distintos elementos para cada módulo. La implantación se realizará a través de soluciones de plantillas y procesos de CI/CD del ámbito DevSecOps.
Módulo de Integración
Se dispone de sistemas de streaming de datos e Internet Of Things (IOT), integrando batch de ficheros, APIs y repositorios de datos. Se utiliza para ingesta datos en la plataforma en la primera capa RAW del Data Lake en modo streaming o batch, siendo el punto de entrada de datos en el sistema.
Módulo de Transformación
Permite el procesamiento en Real Time (RT), Near Real Time (NRT) y Batch. Los componentes en tiempo real deben ser capaces de ofrecer latencias bajas, mientras que las otras dos deben ser escalables y adaptables a diferentes volumetrías. Se utiliza para procesar los datos mediante ETLs para transformar los datos y avanzar por la jerarquía hacia el Data Warehouse con datos procesados.
Módulo de Calidad
Se consideran dos capas diferenciadas para la calidad del dato: desde la capa Global de Gobierno con los estándares y reglas comunes, y desde cada dominio que debe aplicar e implementar dichas reglas. Utilizado como base del contrato de calidad que deberán cumplir los productores y consumidores para asegurar la integridad de la calidad.
Módulo Datalake
Se considera un enfoque Data Lakehouse, combinando los modelos de Datalake con Data Warehouse, ofreciendo almacenamiento por tipo de dato (estructurado, semiestructurado, no estructurado). Se utiliza como almacenamiento de los datos durante el ciclo de vida en la plataforma, desde la ingesta y conforme se va procesando hasta que constituyen datos listos para su consumo.
Módulo de Analítica Avanzada
Se considera una arquitectura de componentes Machine Learning Operations (MLOps), que cubre el ciclo de vida de los modelos de inteligencia artificial: descubrimiento de los catálogos de datos, preparación de las interfaces de acceso, análisis y manipulación, modelado del código para los modelos de IA y ejecución de los modelos, trazando y monitorizando durante la ejecución para detectar anomalías. Se utiliza para entrenar modelos de Inteligencia Artificial y poder utilizarlos para realizar predicciones sobre los datos.
Módulo de Reporting
Este módulo contiene diferentes tipos de reportes. Dichos tipos consideran reporting BI, centrado en la generación de cuadros operativos, mando o dirección, informes por dominio, logs y métricas permiten tener una visualización de datos específica de un dominio o departamento enfocado en Business Activity Monitoring (BAM), para permitir tomar decisiones basadas en el seguimiento de procesos de negocio, o informes de integración discover de datos para la realización del discover de datos en el Data Lake, como exploración de esquemas, tablas, etc. Utilizado para generar cuadros de mando operativos y reportes.
Plano de dominios y productos
Esta capa incluye los productos de datos organizados por dominios de negocio, utilizando un modelo Data Mesh descentralizado de tipo Hub & Spoke, lo cual implica dos grandes elementos: un Data Hub que ejerce de pieza centralizadora de servicios como el Data Lake, la plataforma de Streaming, el Data Marketplace y los elementos de Gobierno Técnico y, por otro lado, un elemento integrador de los dominios.
Data Lakehouse
Pieza encargada de generar los distintos dominios de datos en base a los datos ingestados. Cada dominio implementa su propio Lakehouse dividido en 3 capas:
- Capa RAW inicial donde se realiza la ingesta. Posee dos subcapas: landing, que almacena los formatos originales sin transformaciones, y staging, donde se aplican reglas de calidad iniciales, enfocadas a conversión de tipos de datos requeridos.
- Capa empresarial: diferencia los datos en una visión por dominios, centrada en la gestión y control de fuentes de datos. En esta capa, se realizan transformaciones de renombrado de campos, agregación de datos, limpieza de datos crudos, borrado de duplicados.
- Capa de consumo, orientada a los consumos específicos de datos. Utiliza los datos de la capa anterior para realizar análisis, generar informes o generar modelos predictivos entre otros. Puede aplicar transformaciones adicionales según las necesidades específicas.
Streaming Platform
Se consideran distintas opciones de procesamiento según si se trata de datos Real Time (RT), con conectores que permiten mover la información directamente a sistemas de almacenamiento para ser consumidos por el destino, o Near Real Time (NRT), que puede soportar procesamientos masivos en caso de ser necesario.
Marketplace
Componente que permite a los consumidores visualizar el catálogo completo de productos de datos disponibles en una solución de gobierno del dato. Permite consultar los metadatos, descripciones o ejemplos de datos. Los datos que se publican cumplirán la auditoría de calidad exigida.
Gobierno Técnico del Dato
Contempla diccionarios de datos y glosarios de negocio, manteniendo en una única plataforma la visión de todos los datos de la organización. Permite conocer el estado de los datos, la definición, explotación y origen. Este servicio cubre las necesidades de seguridad de los datos mediante la visibilidad, el autodescubrimiento de los datos, brindar un buscador semántico, unificar los activos de los datos en una única plataforma, trazar el ciclo de vida de los datos sensibles, catalogar los conjuntos de datos, ofrecer patrones personalizados para los algoritmos de Machine Learning, y gestionar la conectividad de múltiples orígenes de datos.
MDM (Master Data Management)
Permite gestionar los metadatos a través de un Golden Record, pudiendo estar asociado a distintas tipologías de datos (ciudadano, empresa, licitación, etc). Se suscribe a los productos de datos de cada dominio de datos, los cuales son propietarios de los datos, pero con una visión parcial, generando una visión consolidada que asegurará la mejor versión del dato y su disponibilidad para el consumo por los dominios.
Plano de operaciones
Esta capa engloba servicios y herramientas asociados a la operación y mantenimiento de la plataforma. Optimiza la experiencia para operar, gobernar y consultar el conjunto de productos de datos.
Seguridad
Centraliza la gestión de acceso a la plataforma y aplica las funciones necesarias para la gestión de los datos de forma segura. Se operativizará en la plataforma con el objetivo de gestionar los accesos a las diferentes tipologías de datos de la organización en función de las tipologías de usuarios y los niveles de confidencialidad y protección de los datos existentes. Se consideran los escenarios de enmascarado de datos persistentes, donde se enmascaran cuando se carga o transforman y se almacenan enmascarados, y enmascarado de datos dinámicos, donde se enmascaran o no según el rol del usuario en el momento de la consulta.
Gobierno del dato
Ofrece dos perspectivas: enfoque centralizado, centrado en políticas y procedimientos generales de gobierno; y enfoque federado, operativizando el gobierno técnico de los datos adoptando las políticas y procedimientos que se han definido a nivel global. Cada dominio asume la responsabilidad de algunos aspectos del gobierno en lugar de ser asumidas por un equipo global.
Monitorización
Permite llevar un seguimiento y control integral de los procesos, flujos de trabajo y servicios y plataforma, así como maximizar el rendimiento, capacidad y la disponibilidad de los recursos e identificar de forma proactiva los problemas.
Patrones de arquitectura y diseño
En el diseño de una arquitectura de datos, se pueden identificar varios patrones que representan soluciones probadas y recurrentes a desafíos comunes:
- Data Warehouse
- Data Lake
- Data Lakehouse
- Data Mart
- Data Pipeline
- Data Mesh
- Data Fabric
- Arquitectura lambda
Data warehouse
Almacén que integra datos de diversas fuentes para proporcionar una visión unificada y coherente de la información, con estructura relacional, optimizado para análisis de datos e informes. Utilizan esquemas de datos específicos como los siguientes:
Esquema en estrella
Se caracteriza por unas tablas de hechos conectadas a diferentes tablas de dimensiones que representan las entidades de datos agregados.
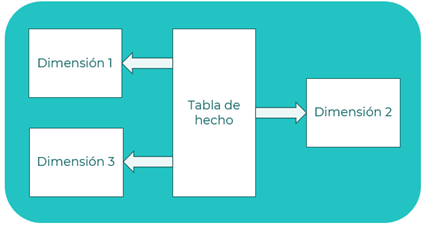
Principios que aplican:
- Desacoplamiento de componentes
- Fuente única de verdad
- Cloud Ready & Cloud Native
Esquema copo de nieve
Similar al esquema en estrella, pero con tablas de dimensiones adicionales conectadas a otras tablas de dimensiones para representar jerarquías dimensionales.
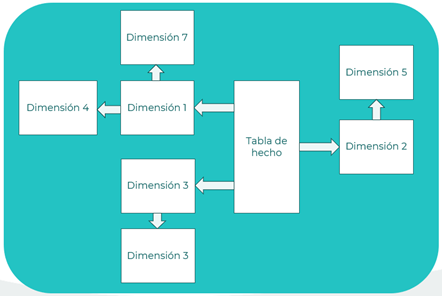
Principios que aplican:
- Desacoplamiento de componentes
- Fuente única de verdad
- Cloud Ready & Cloud Native
- Privacidad
Referencias:
Data lake
Un data lake es un repositorio centralizado que permite almacenar información estructurada (tablas de base de datos, hojas de cálculo), semi estructurada (ficheros XML, ficheros web) y desestructurada (imágenes, ficheros de audio y video) a cualquier escala. La información se suele almacenar en capas (capa de datos crudos, capa de datos curados, capa de consumo) facilitando el control de acceso, el gobierno y el procesamiento del dato. Generalmente se almacenan los datos en su formato original, denominados datos crudos, y pueden ser ingestados utilizando procesos ELT, que cargan los datos antes de transformarlos, preservando la estructura original de la fuente de origen y, posteriormente, se procesarán para poder ser utilizados para análisis. Cada tipo de usuario podrá usar los datos en la capa que necesite, permitiendo una gran variedad de aplicaciones, como analíticas de Big Data, Machine Learning, analítica predictiva y otros tipos de Inteligencia Artificial.
Principios que aplican:
- Cloud Ready & Cloud Native
- Privacidad
Referencias:
Data lakehouse
Patrón que combina características de un data lake y un data warehouse para gestionar y analizar datos de manera integral. Combina la flexibilidad y escalabilidad de un data lake, que permite almacenar datos de cualquier formato y tipo, con la estructura y el rendimiento optimizado para análisis de un data warehouse. Es una evolución reciente de arquitectura para abordar las limitaciones de los sistemas de bases de datos tradicionales ofreciendo escalabilidad y flexibilidad. Igual que en un data lake, los datos son almacenados en bruto, pero posteriormente, son estructurados y transformados en un modelo optimizado para reportes o análisis, igual que ocurre en un data warehouse, permitiendo el tratamiento de datos en tiempo real de un modo eficiente. Igualmente, permite la integración de datos en tiempo real, permitiendo acceder a datos más actualizados, facilitando la escalabilidad y flexibilidad y permitiendo una buena toma de decisiones. También permite distribuir el almacenamiento entre sistemas on-premises y cloud.
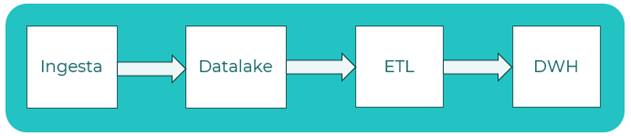
Principios que aplican:
- Cloud Ready & Cloud Native
- Fuente única de verdad
Referencias:
Data mart
Un data mart es una subsección o subconjunto especializado de un data warehouse que se centra en un área específica como un departamento o una unidad de negocio. Utilizan datos resumidos que permite a cada departamento tomar decisiones más rápidamente. Pueden ser de tipo dependiente (recopila información de un origen centralizado), independiente (no depende de otros orígenes centralizados ni de otros data mart) o híbridos (recopilan información de fuentes centralizadas y externas). Igualmente, pueden usar una estructura en estrella (con tabla central y ramificaciones de dimensiones) o desnormalizado (almacenando todos los datos en una única tabla).
Principios que aplican:
- Cloud Ready & Cloud Native
- Privacidad
Referencias:
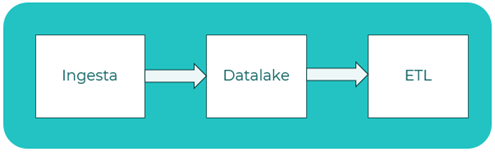
Data pipeline
Un data pipeline consiste en flujo de procesamiento en el que se va tratando el dato. Puede subdividirse en:
ETL (Extract, Transform and Load)
Aproximación tradicional en la que se extrae el dato y posteriormente se procesa antes de cargarlo en el data warehouse.
ELT (Extract, Load and Transform)
Aproximación moderna en la que el dato crudo se almacena directamente y las transformaciones se realizan a posteriori, a menudo en un data lake.
Principios que aplican:
- Integración e interoperabilidad
- Curación de lo datos
- Cloud Ready & Cloud Native
Referencias:
Data mesh
Un enfoque emergente que se centra en la descentralización y la autonomía de los dominios de datos al tratar el dato como un producto. Propone organizar la arquitectura de datos en torno a dominios y equipos de productos de datos. Ofrece un enfoque de tratar los datos como productos, de modo que cada departamento se encarga de los datos que le corresponden, dividiendo en equipos el tratamiento, la gestión y las normas de los datos, y además permitiendo que la estructura organizativa del proyecto crezca con el tiempo, agregándose nuevos departamentos con sus datos correspondientes y permitiendo la arquitectura de datos crecer.
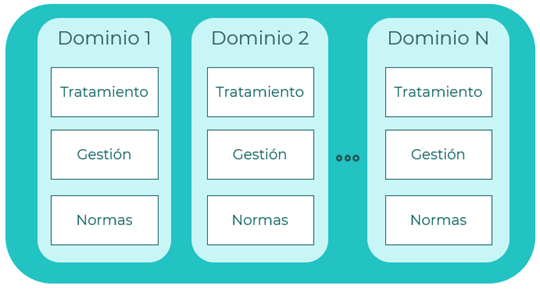
Principios que aplican:
- Desacoplamiento de componentes
- Fuente única de verdad
- Cloud Ready & Cloud Native
- Privacidad
Referencias:
Data fabric
Data Fabric se refiere a una arquitectura que busca unificar y simplificar la gestión de datos en entornos distribuidos y heterogéneos. Esta estructura proporciona una capa cohesiva que conecta diversas fuentes de datos, ya sean locales o en la nube, permitiendo a las organizaciones gestionar y aprovechar su información de manera más eficiente. Permite unificar distintas fuentes de datos y aplicaciones ofreciendo una solución a los continuos cambios en los complejos sistemas de almacenamiento que generalmente engloban múltiples plataformas con base de datos, data warehouses, etc donde residen los datos. Permite ofrecer acceso a los datos de los diferentes sistemas de forma segura sin tener que migrarlos a una plataforma común, no forzando la centralización de los datos, sino favoreciendo los sistemas distribuidos y heterogéneos coexistir para ser flexibles a cambios o adiciones de fuentes de datos, permitiendo a los usuarios finales acceder a esas nuevas fuentes de datos sin tener que reestructurar la arquitectura completa.
Principios que aplican:
- Integración e interoperabilidad
- Fuente única de verdad
- Cloud Ready & Cloud Native
Referencias:
Arquitectura lambda
Diseñada para sistemas de procesamiento de datos en tiempo real y por lotes. Combina capas de procesamiento por lotes y en tiempo real para ofrecer análisis en tiempo real y almacenamiento a largo plazo de datos. Generalmente utilizado para cantidades masivas de datos, donde el procesamiento y las consultas pueden tardar horas, obteniendo posibles datos desactualizados.
Para solventar este problema, se propone esta arquitectura en dos caminos:
- Capa batch (cold path): almacena todos los datos en crudo y los procesa en modo batch, por lotes. El resultado se almacena como una vista batch.
- Capa speed (hot path): analiza los datos en tiempo real, centrado en la baja latencia.
Tras la capa batch, los datos se vuelcan a una capa serving, donde se pueden consultar los datos. La capa speed actualiza la capa serving en base a los datos más recientes. Cada capa cumple con los requisitos de la naturaleza característica de los datos, en base a si se requiere procesar en modo batch por lotes, o modo on-line en tiempo real, volcándose los datos procesados en la capa serving común para ser analizados y utilizados. Los datos de la capa de velocidad podrán usarse en tiempo real pero serán menos precisos que los datos de la capa por lotes, que por otro lado considera cálculos y procesamiento de mayor exactitud a costa del tiempo empleado en dicho procesamiento, por lo que este enfoque en 2 vías es perfecto para cumplir con las necesidades del cliente, sea de tiempo real para informes previos o de exactitud para informes exhaustivos.
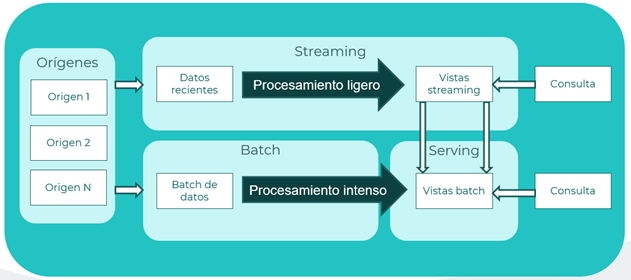
Referencias:
Pila tecnológica
| Componente | Solución | Descripción |
|---|---|---|
Integración de datos | Azure Data Factory | Ofrece una interfaz intuitiva y visual para diseñar pipelines, facilitando la creación y monitoreo de procesos complejos de integración de datos. Además, soporta la integración continua y la entrega continua (CI/CD), lo que agiliza el desarrollo y despliegue de flujos de trabajo. También garantiza la seguridad de los datos con opciones de autenticación y autorización avanzadas y proporciona una alta disponibilidad y tolerancia a fallos para asegurar la confiabilidad de las operaciones de datos. |
Azure Event Hubs | Componente con el que se ingestan datos de diversas fuentes, ofrecen un sistema de colas en tiempo real y almacenan los datos en la primera capa de almacenamiento del lago de datos. | |
Apache Kafka | Plataforma distribuida que permite transmitir datos y procesar flujos de eventos en tiempo real. Funciona como un sistema de colas basado en suscripciones y publicaciones de datos. | |
Synapse | Plataforma de análisis en la nube que combina el almacenamiento de datos con análisis en tiempo real y procesamiento de big data. Permite la integración fluida de datos desde diversas fuentes, tanto estructuradas como no estructuradas, y ofrece potentes capacidades de consulta a través de SQL, Spark, y otros motores. | |
Fabric pipelines | Componente de orquestación de datos dentro del ecosistema Microsoft Fabric. Permite diseñar, automatizar y monitorizar flujos de trabajo de integración y transformación de datos, facilitando la implementación de procesos ETL/ELT de forma eficiente y escalable. | |
| Fabic Notebooks | Entornos interactivos basados en Jupyter dentro de Microsoft Fabric. Soporta múltiples lenguajes como Python y R. | |
Function App | Servicio de computación serverless que permite ejecutar funciones bajo demanda en respuesta a eventos o desencadenadores. | |
Data lake | Azure Data Lake Storage | Componente diseñado para manejar grandes volúmenes de datos no estructurados y estructurados, permitiendo un acceso rápido y seguro a los datos para análisis, machine learning y procesamiento distribuido. |
One lake | Lago de datos unificado de Microsoft Fabric. Actúa como repositorio centralizado para todos los datos, permitiendo el acceso federado desde distintas herramientas analíticas sin necesidad de replicación. | |
Data lakehouse | Delta Lake | Proporciona la capa de almacenamiento transaccional que permite a un data lake tener características propias de un data warehouse al ofrecer soporte para transacciones ACID, versiones de datos, y un sistema de manejo de metadatos que mejora la confiabilidad, la consistencia y el rendimiento de las operaciones de datos. |
| Fabic Lakehouse | Arquitectura de datos moderna que combina las capacidades de un data lake con las ventajas de un data warehouse. Permite almacenar datos estructurados y no estructurados en One Lake, ofreciendo acceso mediante SQL y soporte para cargas analíticas avanzadas. | |
| SQL | Azure SQL | Servicio de base de datos relacional. Proporciona una plataforma altamente disponible, segura y escalable para aplicaciones transaccionales, con capacidades avanzadas de gestión, replicación y recuperación ante desastres. |
| Fabric SQL | Motor de consultas SQL optimizado para Microsoft Fabric. Facilita el análisis de grandes volúmenes de datos almacenados en One Lake y Lakehouse, permitiendo consultas analíticas de alto rendimiento con integración nativa en el entorno Fabric. | |
| Almacenamiento por bloques | Blob Storage | Servicio de almacenamiento de objetos diseñado para almacenar grandes volúmenes de datos no estructurados, como archivos multimedia, documentos, backups y datos en bruto, con alta durabilidad y escalabilidad. |
| Visualización | PowerBI | Permite crear dashboards interactivos, informes detallados y gráficos personalizados al conectar, transformar datos de diversas fuentes en tiempo real. |
| Tableau | Plataforma de análisis visual que permite explorar y administrar los datos con herramientas avanzadas. Permite crear reportes y cuadros de mando con una interfaz intuitiva de arrastrar y soltar. | |
| IA | Machine Learning | Permite el desarrollo, entrenamiento, implementación y gestión de modelos de aprendizaje automático. Facilita la creación de soluciones predictivas y prescriptivas mediante flujos de trabajo automatizados y escalables. |
| AI Foundry | Proporciona acceso a modelos de IA generativa, herramientas de personalización y capacidades de integración para acelerar el desarrollo de soluciones inteligentes. | |
| Seguridad | Key Vault | Servicio de gestión de secretos. Permite almacenar y controlar el acceso a claves, contraseñas, certificados y otros secretos críticos, garantizando la seguridad de los activos digitales mediante políticas de acceso y auditoría centralizadas. |
Conexión con la red de la Junta de Andalucía
Dado que la solución para la arquitectura de datos se ha definido con elementos de Azure, ha sido necesario definir un método de conexión con el resto de elementos existentes en la red de la Junta de Andalucía, incluyendo aquellos desplegados para el resto de arquitecturas con OpenShift.
Dentro del tenant corporativo se ha creado una suscripción dedicada a la interconexión con la red de la Junta de Andalucía de forma que, a través de una VPN, se permite la conexión con cualquier elemento de la red. Junto a la VPN también se ha desplegado un firewall, de forma que todo el tráfico se deniega por defecto. Por tanto, cada caso de uso requerirá realizar una solicitud para habilitar la visibilidad necesaria.
Escenarios de aplicación
A continuación, se van a mostrar una serie de escenarios de aplicación donde se puede aplicar la arquitectura de datos.
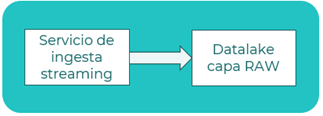
Modelo de ingesta streaming
Escenario
Se define un escenario de ingesta con un servicio ingestando los datos en modo streaming (RT).
Descripción
- Ingesta streaming: lee los datos en modo streaming (real time) del origen. Supone una sustitución de un pipeline ETL permitiendo transformación de los datos en el flujo.
- Data lake: almacena los datos en almacenamiento en la capa RAW, manteniendo el formato origen de los datos.
Patrones
- Data lake
- Data pipeline
Modelo de ingesta batch con orquestación
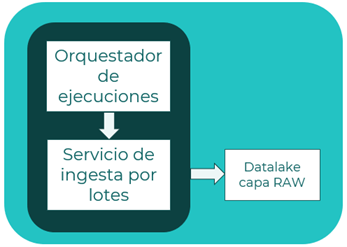
Escenario
Se define un escenario de ingesta de datos en modo batch, con un servicio recolectando los datos en modo batch, y un servicio orquestador lanzando las ejecuciones planificadas.
Descripción
- Servicio orquestador: consta de planificaciones de ejecuciones de workflows DAG para la ejecución de la ingesta con el servicio de ingesta por lotes.
- Servicio de ingesta: lee los datos en modo batch (por lotes) del origen con una programación (scheduling). Permite cierto procesamiento en la lectura de origen.
- Data lake: almacena los datos en almacenamiento en la capa RAW.
Patrones
- Data lake
- Data pipeline
Procesamiento distribuido de datos
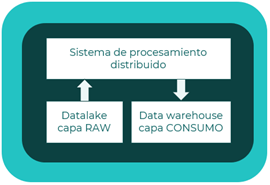
Escenario
Se define un escenario de procesamiento de datos distribuido con un servicio de procesamiento de los datos del Datalake.
Descripción
- Sistema de procesamiento: permite el procesamiento distribuido entre las distintas máquinas del clúster.
- Data lakehouse: procesa los datos del datalake y los almacena en el almacenamiento estructurado data warehouse.
Patrones
- Data lake
- Data pipeline
Generación de reporting
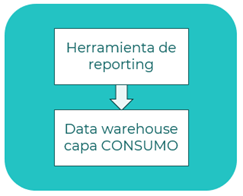
Escenario
Se define un escenario de generación de reporting.
Descripción
- Herramienta de reporting: genera los reportes como visualización gráfica de los datos almacenados en la capa de Consumo.
- Data warehouse: contiene los datos procesados que utilizará la herramienta para generar los reportes.
Patrones
- Data warehouse
Referencias
Referencias técnicas: