Información general

La definición de esta arquitectura debe tener en cuenta los requerimientos normativos, funcionales y tecnológicos de las iniciativas presentes y futuras dentro de la organización, asegurando una cobertura completa.
Dentro de una organización, la arquitectura de observabilidad tiene como objetivo proporcionar una visión integral del estado y el rendimiento de la infraestructura y las aplicaciones. Por lo tanto, es necesario definir un modelo de arquitectura de referencia que permita establecer unos requerimientos, reglas y pautas corporativas de obligado cumplimiento para los nuevos desarrollos dentro del ámbito de la ADA.
Este artículo está dirigido a los equipos de desarrollo de la Junta de Andalucía, Dirección de Proyectos tecnológicos, y las distintas Subdirecciones de la Agencia Digital de Andalucía.
Objetivos, características y beneficios
La observabilidad es una parte transversal a la arquitectura global y cada una de sus partes. Su objetivo principal es la recolección y análisis de métricas, logs y trazas generadas en cada una de las partes que componen la arquitectura y aplicaciones, así como los medios necesarios para explotarlos.
De esta manera, la observabilidad contribuye a proporcionar los datos para poder garantizar el rendimiento, disponibilidad y capacidad de respuesta de las arquitecturas, plataformas y aplicaciones.
Como objetivos secundarios alineados con este objetivo principal, se destacan los siguientes:
- Detección temprana de anomalías: Implementar sistemas de alerta que identifiquen comportamientos anómalos en tiempo real, permitiendo una respuesta rápida y efectiva.
- Diagnóstico de problemas: Facilitar la identificación y resolución de problemas mediante el análisis de logs, correlación de eventos y el análisis de causas raíz.
- Optimización del rendimiento: Utilizar los datos recolectados para identificar cuellos de botella y áreas de mejora en el rendimiento del sistema.
- Mejora continua: Fomentar una cultura de mejora constante basada en datos, donde las decisiones se tomen en función de métricas y análisis objetivos.
- Cumplimiento de SLA: Asegurar que los acuerdos de nivel de servicio (SLA) se cumplan mediante el monitoreo constante y la generación de informes de rendimiento.
Para alcanzar tanto el objetivo principal como los secundarios la arquitectura de observabilidad debe contar con ciertas características esenciales:
- Recolección de datos en tiempo real desde múltiples fuentes.
- Escalabilidad para manejar grandes volúmenes de datos.
- Flexibilidad para integrarse con diversas tecnologías y plataformas.
- Disponer de herramientas avanzadas de análisis y visualización que permitan a los equipos de desarrollo y operaciones interpretar los datos de manera efectiva.
- Automatización de alertas.
- Trazas distribuidas para detectar y diagnosticar problemas rápidamente.
En conjunto, estas características aseguran que la arquitectura de observabilidad no solo soporte el monitoreo continuo del sistema, sino que también facilite la toma de decisiones informadas y la mejora continua del rendimiento y la disponibilidad del sistema. Las propias características de las arquitecturas de observabilidad, y el cumplimiento de los objetivos, tienen una serie de beneficios para la Junta de Andalucía:
- Capacidad de detectar y resolver problemas de forma proactiva reduciendo significativamente el tiempo de inactividad y mejorando la disponibilidad del sistema, lo que se traduce en una mejor experiencia para el usuario final.
- Optimización del rendimiento basándose en datos permiten una utilización más eficiente de los recursos, ahorrando de costos operativos.
- Visibilidad completa y en tiempo real del estado de las plataformas, sistemas y aplicaciones.
- Mejora continua impulsada por la información obtenida, permitiendo a la organización responder rápidamente a cambios en el entorno.
Principios
Partiendo de los principios generales definidos en la arquitectura global de contexto y que aplican en su totalidad a la arquitectura de observabilidad, esta arquitectura posee una serie de principios específicos:
- Medición continua
- Correlación de datos
- Análisis en tiempo real
- Observabilidad por diseño
(*) Puede consultarse el listado de principios tecnológicos generales.
Este principio subraya la importancia de recopilar datos de manera ininterrumpida para comprender el estado y el comportamiento de un sistema o aplicación. A través de métricas, logs y trazas, se obtiene una visión granular del funcionamiento de los componentes, permitiendo identificar tendencias, anomalías y problemas de rendimiento de forma proactiva.
Correlación de datos
La correlación de datos es esencial para obtener una comprensión completa del sistema o aplicación. Al establecer relaciones entre métricas, logs y trazas, se puede identificar cómo interactúan los diferentes componentes y cómo afectan unos a otros. Esto facilita determinar las causas raíz de los problemas y la resolución de incidencias de manera más eficiente.
Análisis en tiempo real
El análisis en tiempo real permite a los equipos de operaciones responder de manera rápida y efectiva a los incidentes y problemas que surjan. A través de visualizaciones interactivas y alertas, se puede monitorear el estado del sistema y detectar anomalías de manera proactiva.
Observabilidad por diseño
La observabilidad debe ser una consideración fundamental desde las primeras etapas del desarrollo de un sistema. Al incorporar la instrumentación en el código desde el inicio, se garantiza que los datos necesarios estén disponibles para el análisis y la resolución de problemas.
Componentes
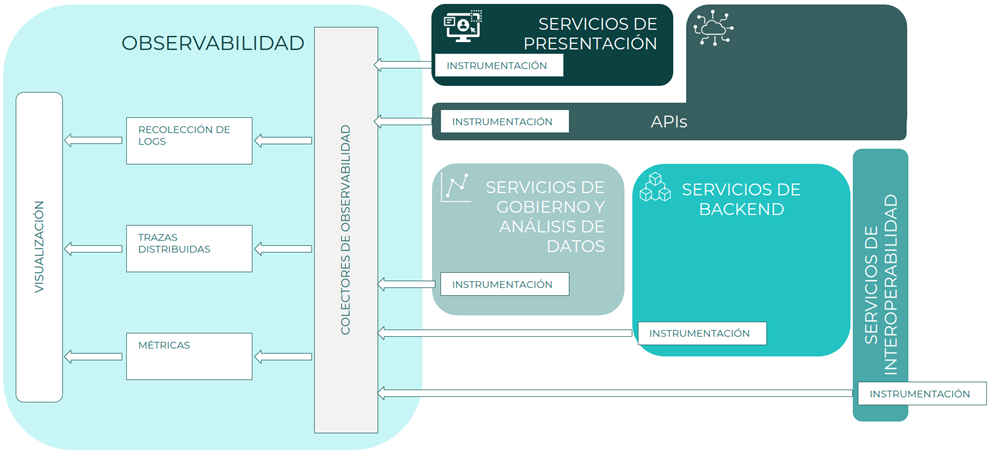
Instrumentación
El punto de partida de toda estrategia de observabilidad parte de la creación de los datos de telemetría de cada uno de los sistemas. Estos pueden ir desde servicios a herramientas complejas. Para obtener la información de telemetría se dispone de dos estrategias: la creación de telemetría de forma manual o automática
- Manual: Esta estrategia se basa en añadir al código de aplicación las instrucciones necesarias para crear y exportar la información de telemetría. Es habitual apoyarse en librerías incorporadas a la aplicación para facilitar esta tarea. Por ejemplo: el conocido Log4j usado para la creación de logs o el SDK de OpenTelemetry. Esta estrategia se puede usar cuando se tiene el control del código de la aplicación, ya que la integración de las instrucciones necesarias es significativamente más sencilla.
- Automática: En aquellos casos en los que incorporar las instrucciones que nos permitan generar la información de telemetría sea más complejo o directamente inviable, se pueden utilizar herramientas y librerías para instrumentar automáticamente frameworks y bibliotecas comunes, creando y exportando datos de telemetría. Esta estrategia es posible aplicarla solo en los casos en lo que podamos añadir a la aplicación un sidecar responsable de la instrumentación automática.
Colectores
Los colectores son componentes que recogen la información que se envía desde la instrumentación. Estos componentes tienen algunas características adicionales ,como por ejemplo, el ser stateless. Es decir, que su ejecución no depende del estado de la aplicación. Esto permite que puedan escalar para dar servicio a un volumen creciente de información entrante, sin que ello afecte a la información que estén tratando.
La información de telemetría que reciben se redirige y exporta a los sistemas de terceros. Este flujo se define con pipelines internos configurables en el colector. La información de entrada puede tratarse en uno o varios pipelines y en cada pipeline, se puede agrupar y/o filtrar la información antes de ser exportada.
La exportación de la información se envía a los Backend responsables de su almacenamiento, análisis y explotación, aunque no está limitado a ello, ya que puede enviarse a otro colector o sistemas intermedios como kafka o incluso a una consola. La principal ventaja de usar un colector en vez de mandar directamente la información recopilada al backend es que, las aplicaciones o componentes software que generan la información, pueden trabajar sin que le afecten los cambios o la posible indisponibilidad del backend.
Logs
Componente responsable de la ingesta, agrupación, tratamiento y exportación de logs enviados por los distintos colectores, aplicaciones, componentes o plataformas. Dentro del flujo habitual de una arquitectura de observabilidad, los colectores envían los distintos logs de las aplicaciones, componentes de las arquitecturas o plataformas al sistema centralizado de logs, que se encarga de almacenar e indexar la información para que esté disponible para su explotación.
Métricas
Componente encargado del registro de métricas para su agrupación, almacenamiento y explotación de la información. Comprenderá tanto métricas técnicas como funcionales, siendo responsabilidad de las aplicaciones o componentes el envío de estas. Dentro del flujo de ingesta, los colectores envían las distintas métricas de las aplicaciones, componentes o plataformas al sistema centralizado de métricas, que será el encargado de almacenar e indexar la información para que esté disponible para su explotación.
Trazas distribuidas
Componente responsable de gobernar las trazas distribuidas de las aplicaciones y posibilitar la correlación de transacciones entre distintos componentes, para su posterior estudio y explotación. Dentro del flujo de ingesta, los colectores envían la información de las trazas de las distintas aplicaciones o componentes software al sistema centralizado de trazas distribuidas, que es el encargado de almacenar, correlar, agrupar y posibilitar la explotación de las trazas al usuario final.
Visualización
Los componentes de visualización son los responsables de proporcionar la información almacenada en los sistemas de logs, métricas y trazas de forma comprensible al usuario final. Esto incluye:
- gráficos para valores numéricos,
- acceso a información de log o traza,
- consultas personalizadas,
- alarmas o alertas,
- etc.
Usualmente, los componentes de visualización muestran esta información mediante cuadros de mando configurables. Estos, permiten determinar patrones y tendencias posibilitando anticiparse a posibles problemas, rastrear errores o tener una visión general del comportamiento de toda la aplicación, arquitectura o plataforma.
Patrones de arquitectura y diseño
A continuación, se identifican los componentes principales que conforman la arquitectura de referencia de observabilidad.
Patrón sidecar
El patrón sidecar es un patrón de diseño que se utiliza en contenedores y sistemas de microservicios para agregar funcionalidades adicionales a una aplicación principal. En el contexto de la observabilidad, el sidecar se encarga de recopilar y enviar logs, métricas y otros datos de telemetría para monitorear y depurar la aplicación. Usualmente se utilizará para la instrumentación automática.
Principios que aplican:
- Calidad el servicio
- Observabilidad por diseño
Distributed tracing
Este patrón permite seguir el recorrido de una solicitud a través de múltiples servicios, creando un rastro que muestra las diferentes etapas de procesamiento y los tiempos de respuesta de cada una.
Principios que aplican:
- Calidad el servicio
- Resiliencia sobre recuperación
- Visibilidad & Trazabilidad
- Observabilidad por diseño
- Correlación de Datos
- Análisis en Tiempo Real
Log Aggregation
El propósito de este patrón es recopilar logs de múltiples fuentes y centralizarlos en un único lugar para su análisis. Esto permite buscar, filtrar y correlacionar los logs para identificar problemas y entender el comportamiento del sistema.
Principios que aplican:
- Calidad el servicio
- Resiliencia sobre recuperación
- Visibilidad & Trazabilidad
- Observabilidad por diseño
- Correlación de Datos
- Análisis en Tiempo Real
Metrics Collection
Application metrics o Metrics collection es un patrón consistente en la recopilación de datos cuantitativos sobre el rendimiento del sistema, como el uso de CPU, memoria, latencia de las solicitudes, entre otros. Estos datos se almacenan y se visualizan en gráficos para identificar tendencias y detectar anomalías.
Principios que aplican:
- Calidad el servicio
- Resiliencia sobre recuperación
- Visibilidad & Trazabilidad
- Medición Continua
- Análisis en Tiempo Real
Health Check
Health Check API consiste en exponer una endpoint (o punto de acceso) en una aplicación o servicio que permita verificar su estado de salud de manera rápida y sencilla. Esta endpoint devuelve una respuesta indicando si el servicio está funcionando correctamente y si todos sus componentes internos son accesibles. Al implementar este patrón, se facilita el monitoreo continuo de la salud de los servicios, la detección temprana de fallos y la creación de alertas automáticas, lo que contribuye a mejorar la resiliencia y disponibilidad de los sistemas. Además, el Health Check API es un componente clave en las estrategias de auto curación, ya que permite a los sistemas detectar problemas por sí mismos y tomar acciones correctivas, como reiniciar servicios o escalar recursos.
Principios que aplican:
- Calidad el servicio
- Resiliencia sobre recuperación
- Medición Continua
Pila tecnológica
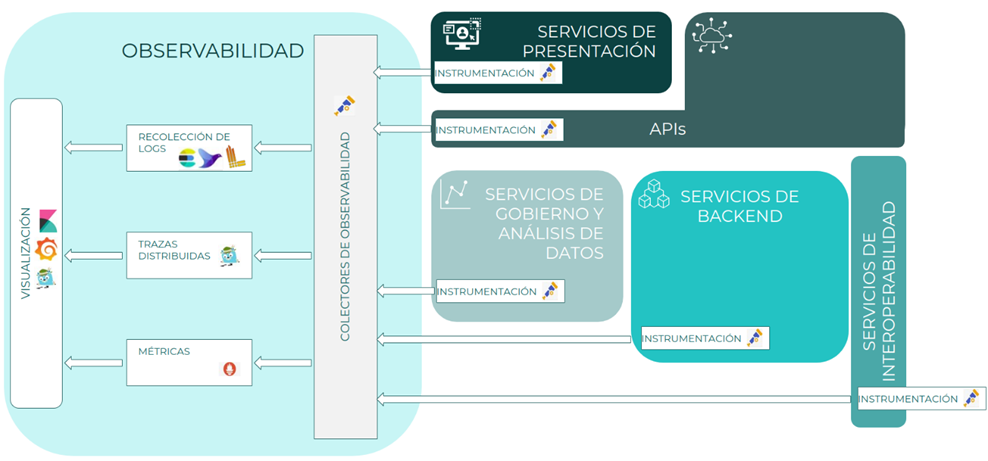
| Componente | Solución | Descripción |
|---|---|---|
Instrumentación | - Opentelemetry (SDK, agents) | OpenTelemetry se plantea como el core de la solución, por lo que siempre que sea posible la instrumentación, se realizará mediante este framework y toolkit. |
Colector de observabilidad | OpenTelemetry Collector | Se desplegarán los colectores de Open Telemetry para realizar la ingesta de logs, trazas y métricas, y luego poder exportarla a los sistemas destino correspondientes mediante configuración sencilla. |
Recolección de Logs | - Fluentd + ElasticSearch - Grafana Loki | Existen dos sistemas de recolección de logs, para que cada proyecto o iniciativa utilice el que mejor se adapte a sus necesidades: 2. Grafana Loki. (Equipos de desarrollo u operación que vayan a visualizar la información de logs en el visualizador de Grafana, teniendo todo integrado)
|
Trazas distribuidas | Jaeger | Jaeger es el componente que se utilizará para la recogida, correlación y agrupación de trazas, siendo compatible con OpenTelemetry y sus colectores. |
Métricas | Prometheus | El sistema de recolección de métricas estará basado en Prometheus, siendo uno de los estándares de facto para el tratamiento de métricas, incorporando además características de alarmas configurables en función de las métricas. |
Visualizadores Logs | Kibana Grafana | Existirán dos visualizadores de logs, en función del perfil y del sistema de logs utilizado para un proyecto o iniciativa:
|
Visualizadores Trazas
| Jaeger UI Grafana | Existirán dos visualizadores de trazas, en función del perfil y del sistema de logs utilizado para un proyecto o iniciativa:
|
Visualizadores Métricas
| Grafana | Grafana se utilizará como sistema principal de visualización de métricas, tanto técnicas como funcionales, de las distintas aplicaciones. |
Escenarios de aplicación
Envío de logs de aplicación
Escenario
Una aplicación envía los logs de distintos componentes a la plataforma de observabilidad, para poder analizar los logs de sus componentes desde un visualizador.
Descripción
Suponiendo una aplicación básica formada por varios MicroFrontEnd y Microservicios, se utilizará el colector de OpenTelemetry para recoger los logs y exportarlos al sistema de Logs:
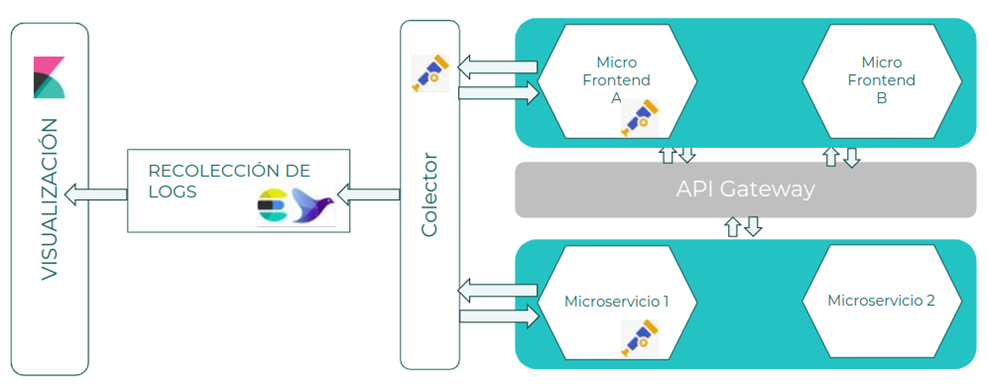
- Micro FrontEnd A: MicroFrontEnd que consume una API del API Manager para mostrar datos al usuario. Se configura la instrumentación por defecto de OpenTelemetry para enviar la información de los logs al colector.
- Microservicio 1: Microservicio que proporciona información y la publica a través de una API. Se configura la instrumentación por defecto de OpenTelemetry para enviar la información de logs al colector.
- Colector OpenTelemetry: Componente encargado de recibir la información de logs, tratarla si es necesario y exportarla a los sistemas que estén configurados.
Patrones
- Log Aggregation
Envío de trazas de aplicación
Escenario
Una aplicación envía trazas de ejecución de distintos componentes a la plataforma de observabilidad, para poder analizar las trazas correladas de sus componentes desde un visualizador.
Descripción
Suponiendo una aplicación básica formada por varios MicroFrontEnd y Microservicios, se utilizará el colector de OpenTelemetry para recoger las trazas, y exportarlas al sistema de trazas distribuidas:
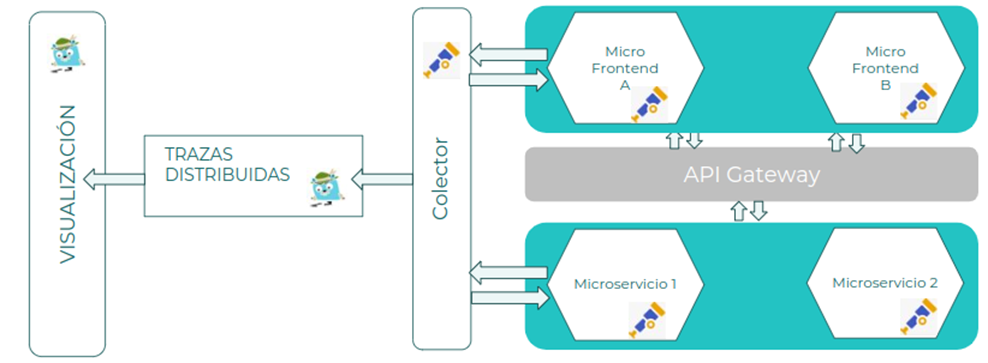
- MicroFrontEnd A: MicroFrontEnd que consume una API del API Manager para mostrar datos al usuario. Se configura la instrumentación por defecto de OpenTelemetry para enviar la información de las trazas al colector. El Micro FrontEnd es el encargado de generar las trazas necesarias y enviar adecuadamente los valores para el trace_id, span_id y parent_id.
- Microservicio 1: Microservicio que proporciona información, y la publica a través de una API. Se configura la instrumentación por defecto de OpenTelemetry para enviar la información de logs al colector. El Microservicio es el encargado de generar las trazas necesarias y enviar adecuadamente los valores para trace_id, span_id y parent_id.
- Colector OpenTelemetry: Componente encargado de recibir la información de trazas, tratarla si es necesario y exportarla a los sistemas que estén configurados.
Patrones
- Distributed Tracing
Envío de métricas de aplicación
Escenario
Una aplicación envía métricas de distintos componentes a la plataforma de observabilidad para poder analizar las métricas de sus componentes desde un visualizador.
Descripción
Suponiendo una aplicación básica formada por varios MicroFrontEnd y Microservicios, se utilizará el colector de OpenTelemetry para recoger las métricas y exportarlas al sistema de recolección de métricas:
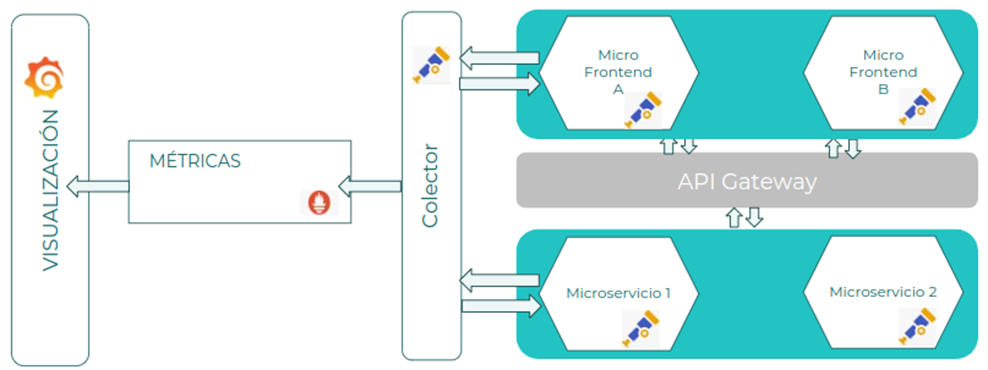
- MicroFrontEnd A: Micro FrontEnd que consume una API del API Manager para mostrar datos al usuario. Se configura la instrumentación por defecto de OpenTelemetry para enviar la información de las métricas al colector.
- Métricas técnicas: Normalmente, la mayoría de frameworks tienen librerías que permite el envío de métricas automáticas cada cierto tiempo al colector. Envían información técnica principalmente del estado del componente.
- Métricas funcionales: El componente es el encargado de generar y gestionar las distintas métricas funcionales que quiera añadir para posteriormente poder explotar la información. Por ejemplo: Número de usuarios activos, tiempo medio de sesión del usuario, usuario web, usuarios móvil, usuarios conectados por organización y departamento, etc...
- Microservicio 1: Microservicio que proporciona información, la publica a través de una API. Se configura la instrumentación por defecto de OpenTelemetry para enviar la información de los logs al colector. El Microservicio es el encargado de generar las trazas necesarias y enviar adecuadamente los valores para el trace_id, span_id y parent_id.
- Colector OpenTelemetry: Componente encargado de recibir la información de trazas, tratarla si es necesario, y exportarla a los sistemas que estén configurados.
Patrones
- Metrics Collection
Referencias
Referencias técnicas: