Esta entrada describe las normas a aplicar para la gestión del código y dependencias en el ámbito de la Plataforma Pre-Cloud.
Todos los componentes tendrán una estructura estándar que facilite la ejecución de procesos de compilación y despliegue.
Nota: Gran parte de las normativas definidas a continuación están orientadas aunque no limitadas a tecnologías basadas en Java, debido al alto índice de uso de la misma. Sin embargo muchos de los procesos y normas ya definidos son independientes del stack tecnológico.
Uso del repositorio de código
Obligatorio
El código de los Sistemas de Información será custodiado en el repositorio definido, basado en GitLab, no existiendo otra opción.
Para los Sistemas de Información ya existentes y que utilizan otros repositorios corporativos, existen varias opciones:
- Empezar a trabajar desde una determinada versión con el repositorio en GitLab, dejando el anterior como referencia.
- Realizar una migración del repositorio actual a GitLab. Para ello, la Oficina de Impulso DevSecOps ofrecerá soporte en las tareas de migración.
Se debe versionar todo el código fuente del proyecto, incluyendo:
- Archivos fuentes java, javascript, python, etc.
- Archivos HTML, CSS, plantillas, etc
- Test unitarios
- Pruebas automatizadas
- Ficheros de manifiesto
- Scripts SQL
- etc
No debe incluirse en el repositorio binarios (a excepción de imágenes y otros recursos similares para montar el proyecto).
No debe incluirse en el repositorio los artefactos intermedios de una compilación ni los generados finalmente.
No debe incluirse ficheros o directorios de configuración del IDE utilizando durante el desarrollo.
Se utilizará un fichero ".gitignore" para asegurar que no se incluye en el repositorio contenido no deseado. A continuación mostramos un ejemplo de cómo podría ser dicho fichero para tecnología JAVA:
# Ficheros compilados *.class # Ficheros de log *.log # Ficheros temporales *.tmp *.swp # Relacionados con Eclipse .project .classpath .settings/ # Relacionados con IntelliJ *.iml *.ipr *.iws # Directorio target originado por una tarea de construcción target/
Alineamiento con GitOps
Obligatorio
GitOps es una metodología para la gestión de configuraciones de infraestructura y aplicaciones mediante el uso de Git como repositorio central de verdad. La idea es tratar las configuraciones de infraestructura y aplicaciones como código y utilizar herramientas de Git para controlar su versión y despliegue. Esto permite un mayor control y visibilidad sobre los cambios en la infraestructura y facilita la colaboración y la automatización a los equipos de operaciones. Se fomentará la adopción de esta metodología en el repositorio.
Organización y estructura tipo para un Sistema de Información
Obligatorio
La implementación de una estructura de repositorio en GitLab persigue la consecución de múltiples objetivos estratégicos, en aras de optimizar el ciclo de vida del desarrollo de software. Los principales objetivos son los siguientes:
- Proporcionar una estructura organizativa coherente que simplifique la gestión de proyectos, promoviendo la eficiencia en el desarrollo al reducir la complejidad de navegación y organización de los repositorios.
- Proporcionar una estructura flexible y escalable que se adapte a la diversidad de proyectos y sistemas, permitiendo la gestión eficaz de múltiples niveles de complejidad sin sacrificar la claridad organizativa.
- Establecer una estructura que sirva como base sólida para los nuevos proyectos que ingresan al entorno Pre-Cloud, asegurando una transición suave y coherente hacia esta fase del desarrollo.
- Asegurar la coherencia y compatibilidad en todos los sistemas, facilitando la interoperabilidad con otras herramientas y garantizando una experiencia uniforme para los equipos de desarrollo.
GitLab ofrece dos elementos para jerarquizar los contenidos del repositorio:
- grupos: Actuarán como contenedores de usuarios y proyectos. Facilitan la organización y gestión de permisos dentro del repositorio.
- proyecto: Espacio que contendrá el código para un componente concreto del Sistema de Información.
Estructura
La estructura organizativa en Gitlab se dividirá, principalmente, en N niveles jerárquicos. Cada nivel tiene un propósito específico y sigue una convención de nombres estandarizada (consultar documento de nomenclatura) para facilitar la identificación y gestión de los activos.
Entendemos que esta estructura, podrá adoptarse sin mayores problemas para la mayoría de los Sistemas / Sistemas de Información. Si por alguna razón se necesitase tener una estructura distinta (por ejemplo, establecer una estructura jerárquica mayor), habrá que acordar con la Oficina de Impulso DevSecOps dicha estructura, para identificar potenciales problemas o inconvenientes. No obstante, se seguirán las convenciones propuestas de manera generalizada.
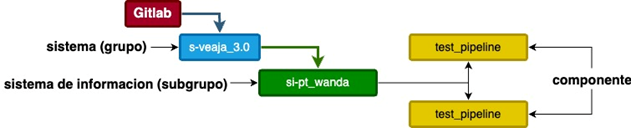
Primer nivel: Sistemas / Sistemas de Información / Servicio de apoyo
El primer nivel, situado en la raíz de Gitlab y representado siempre por un grupo, puede ser uno de los siguientes:
- Sistema: representa una agrupación de Sistemas de Información.
- Sistema de Información: conjunto de activos que engloba elementos de software así como procesos que se implementan para ofrecer uno o más servicios de negocio.
Esta conceptualización implica una integración de componentes que funcionan como un único sistema ante el usuario.
Tiene los mismos responsables tanto de información, como de servicio y del propio sistema, y por ello es tratado como una sola entidad para las tareas de calidad y seguridad. - Servicio de apoyo: servicios de apoyo de la ADA, que se pueden consultar en el Portal de Desarrollo de Sistemas Digitales o en la Intranet de la ADA
Niveles intermedios: Estructura lógica / Sistema de Información
En el segundo nivel, nos podemos encontrar:
- Estructura Lógica: Subgrupos opcionales que podrán ser utilizados para la organización de los componentes de manera lógica y coherente.
- Sistemas de Información: Si en primer nivel se ha definido un Sistema o Servicio de Apoyo, este será el caso. Pueden existir múltiples Sistemas de Información dentro de un Sistema. Se usarán GRUPOS de Gitlab para definir los distintos Sistemas de Información. Una vez creado un Sistema de Información, no podrá existir ningún otro Sistema de Información por debajo de su jerarquía.
Último nivel: Componente
El último nivel, siempre corresponde a los componentes. En este contexto, se entiende como el espacio destinado a contener el código asociado a un Componente específico del Sistema de Información o del Servicio de Apoyo.
Un componente se caracteriza por ser un elemento que proporciona un servicio de software predefinido, con una interfaz claramente definida y capaz de comunicarse con otros componentes
Cada componente es versionable y desplegable de forma independiente, lo que facilita su gestión y mantenimiento dentro del entorno del Sistema de Información o del Servicio de Apoyo.
Ejemplos
A continuación, se presenta un esquema ilustrativo del sistema de organización:

A modo de ejemplo:

Nomenclatura
Obligatorio
Directrices de nomenclatura
En esta sección se detallarán las convenciones para asignar nombres a los grupos, subgrupos y componentes.
Tipos de grupo:
- Sistema
- Sistema de información
- Servicio de apoyo
Para asegurar una nomenclatura coherente y fácil de seguir en GitLab, se aplicarán las siguientes directrices generales:
- Inicio del Nombre:
- Debe comenzar con una letra.
- Cuerpo del Nombre:
- Puede contener letras y números.
- No se permite el uso de caracteres especiales a excepción de los indicados a continuación:
- El guion ("-") se usará para separar el tipo de grupo del nombre.
- El guion bajo ("_") se utilizará para separar distintas partes dentro del nombre.
- El punto (".") no tiene una utilidad específica asignada y puede ser utilizado según sea necesario.
- No se permite el uso de letras mayúsculas en ningún momento, tanto en el inicio como en el cuerpo.
La nomenclatura específica que deberá tener un nombre de grupo o subgrupo será:
- ({tipo de grupo}-{nombre de grupo} donde "tipo de grupo” podrá tomar los siguientes valores:)
- Sistema: s-nombre_del_grupo
- Sistema de información: si-nombre_del_grupo/subgrupo
- Servicio de apoyo: sa-nombre_del_grupo
- Los subgrupos utilizados como Estructura lógica dentro de un Sistema, Sistema de información o un Servicio de apoyo deben seguir las directrices generales. (No tienen "tipo de grupo")
En el caso del nombre de los componentes, se aplicarán las directrices generales.
Ejemplos:
- Sistema
- Sistema de información
Estrategia de ramificación
Obligatorio
Se ha definido una estrategia de ramificación basada en Gitlab Flow, en el que el uso de ramas representan el estado del código en cada entorno de ejecución y el uso de solicitudes de fusión (Merge Requests), para orquestar y garantizar los despliegues.
El detalle de la estrategia a seguir se describe en Estrategia de ramificación.
Política de Versionado Software
Obligatorio
De cara a garantizar que todos los productos o componentes software sigan una política de versionado estándar, se deben aplicar las pautas marcadas por SEMVER (Versionado Semántico), que se resumen a continuación:
- El software que use Versionado Semántico DEBE declarar un elemento de infraestructura, configuración o despliegue. Este, puede ser declarado en el código mismo o existir en documentación estricta que, de cualquier manera, debería ser precisa y completa.
- Un número normal de versión DEBE tomar la forma X.Y.Z donde X, Y, y Z son enteros no negativos. X es la versión “major”, Y es la versión “minor”, y Z es la versión “patch”. Cada elemento DEBE incrementarse numéricamente en incrementos de 1. Por ejemplo: 1.9.0 -> 1.10.0 -> 1.11.0.
- Una vez que un paquete versionado ha sido liberado (release), los contenidos de esa versión NO DEBEN ser modificados. Cualquier modificación DEBE ser liberada como una nueva versión.
- La versión major en cero (0.y.z) es para desarrollo inicial. Cualquier cosa puede cambiar en cualquier momento. El elemento no debe ser considerada estable.
- La versión 1.0.0 define el elemento. La forma en que el número de versión es incrementado después de este release depende de este elemento y de cómo cambia.
- La versión patch Z (x.y.Z | x > 0) DEBE incrementarse cuando se introducen solo arreglos compatibles con la versión anterior. Un arreglo de bug se define como un cambio interno que corrige un comportamiento erróneo.
- La versión minor Y (x.Y.z | x > 0) DEBE ser incrementada si se introduce nueva funcionalidad compatible con la versión anterior. Se DEBE incrementar si cualquier funcionalidad del elemento es marcada como deprecada. PUEDE ser incrementada si se agrega funcionalidad o arreglos considerables al código privado. Puede incluir cambios de nivel patch. La versión patch DEBE ser reseteada a 0 cuando la versión minor es incrementada.
- La versión major X (X.y.z | X > 0) DEBE ser incrementada si cualquier cambio no compatible con la versión anterior es introducido en el elemento. PUEDE incluir cambios de nivel minor y/o patch. Las versiones patch y minor DEBEN ser reseteadas a 0 cuando se incrementa la versión major.
De forma resumida:
- X: Aumentará cuando se producen cambios que rompan la compatibilidad de alguna manera con la versión anterior. (major).
- Y: Aumentará con cada funcionalidad añadida compatible con la versión anterior. (minor).
- Z: Aumentará con correcciones compatibles con la versión anterior. (patch).
Para más información sobre consultar: Versionado Semántico 2.0.0-rc.2 (https://semver.org/lang/es/).