Información general

Introducción
El objetivo principal de este documento es brindar un soporte inicial a los equipos de desarrollo que vayan a interactuar con la plataforma PreCloud de la Agencia Digital de Andalucía, en adelante ADA, y basada en OpenShift, para que puedan realizar una operación básica de los componentes de sus sistemas de información en dicha plataforma. En este documento se mostrarán los casos de uso más habituales y ejemplos de implementación a modo de referencia para que los equipos de desarrollo puedan desarrollar cierta autonomía a la hora de realizar los despliegues en la plataforma.
Como se ha comentado, el objetivo principal es formar sobre el uso de la plataforma y en concreto, sobre los distintos artefactos necesarios para abordar un despliegue. Se indicará cómo realizar las acciones tanto desde la interfaz de OpenShift como desde una interfaz de línea de comandos, aunque estas opciones se dan a modo ilustrativo (solo para uso puntual y en entornos de desarrollo). Se aconseja utilizar una aproximación GitOps, que es una práctica que utiliza un repositorio de Git como fuente única de verdad para gestionar la infraestructura y las aplicaciones. En otras palabras, en GitOps, todo el estado deseado del sistema, incluida la infraestructura, configuración y aplicaciones, se describe en repositorios de Git. Estos repositorios son el punto central desde el cual se despliega, monitoriza y gestiona todo el ciclo de vida de la infraestructura y las aplicaciones, utilizando herramientas concretas que sincroniza el estado deseado en Git en OpenShift.
Entornos OpenShift disponibles
Para los equipos involucrados en el desarrollo de software para la Agencia Digital de Andalucía (ADA) y que desplieguen sus aplicaciones en el entorno PRECLOUD, actualmente hay disponibles cuatro clústeres con los que pueden interactuar:
DES-ZOCO: Clúster de desarrollo/preproducción para los sistemas de información en ZOCO.
DES-CICA: Clúster de desarrollo/preproducción en el entorno para los sistemas de información en CICA.
PRO-ZOCO: Clúster de producción en el entorno ZOCO para los sistemas de información en ZOCO.
PRO-CICA: Clúster de producción en el entorno CICA para los sistemas de información en CICA.
Puede obtener más información de los distintos entornos consultando Entornos de Ejecución del Software bajo DevSecOps.
Overview General OpenShift
Red Hat OpenShift es la plataforma de aplicaciones Platform as a Service (PaaS) de nube híbrida basada en Kubernetes, que facilita la creación de entornos de desarrollo y aplicaciones escalables y descentralizadas. Combina servicios probados y confiables para reducir los problemas a la hora de desarrollar, modernizar, implementar, ejecutar y gestionar las aplicaciones. Además, ofrece una experiencia uniforme en toda la arquitectura local, del extremo de la red y de la nube pública e híbrida, y se pueden implementar soluciones propietarias PaaS, Software as a Service (SaaS) y Containers as a Service (CaaS).
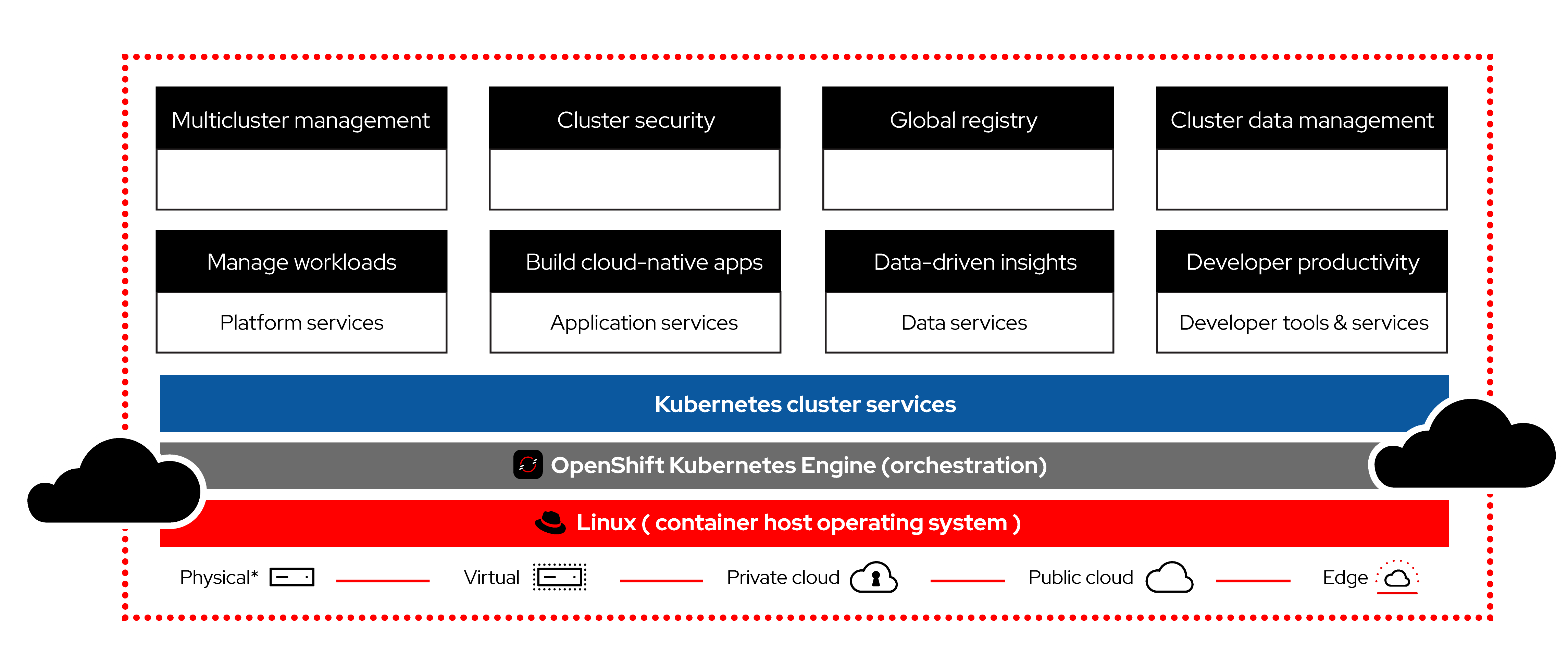
A continuación, se va a realizar una descripción general de la interfaz gráfica de la plataforma OpenShift. A través de ella, los usuarios podrán realizar distintas acciones según la necesidad que tengan.
Para ello, habrá que acceder al entorno de desarrollo correspondiente (CICA o ZOCO), y acceder a la herramienta mediante LDAP_JdA, introduciendo las credenciales de usuario de la intranet de la Junta de Andalucía.
Descripción de la interfaz gráfica
Después de iniciar sesión en OpenShift se cargará la página principal según la perspectiva de usuario. En "Figura 3. Página inicial de OpenShift de un Administrador" podemos ver un ejemplo de la página de inicio para un usuario que ha seleccionado la perspectiva "Administrator".
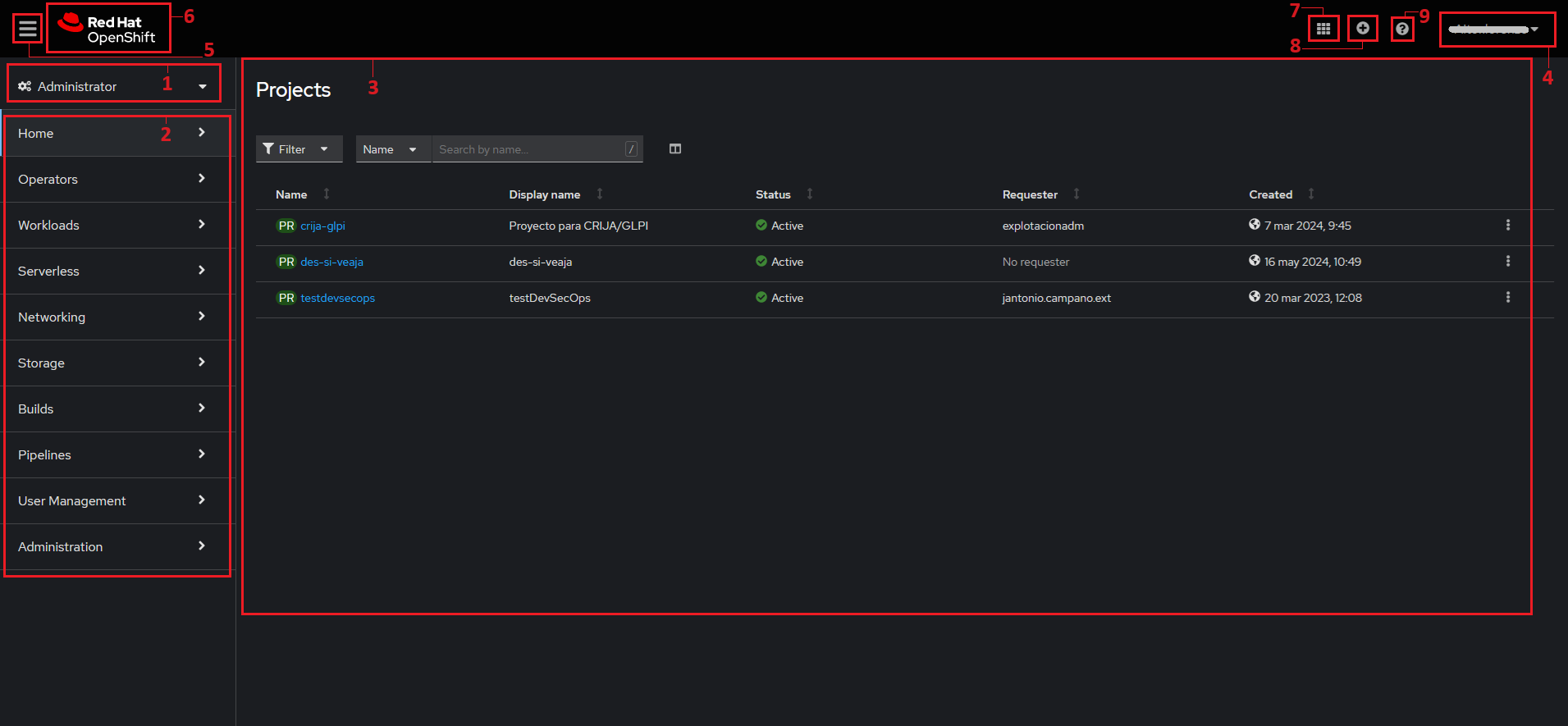
Descripción de los elementos de la página de OpenShift:
- Vista del Usuario: Desplegable para cambiar de vista a Administrator o Developer (depende de los permisos de la cuenta del usuario).
- Menús de OpenShift: Menús de opciones disponibles para la vista seleccionada. Dependiendo de la vista puede tener desplegables con submenús.
- Página principal del Menú/Submenú: Aquí se mostrará la información y opciones del menú o submenú seleccionado.
- Menú del usuario registrado: Permite salir de la plataforma, acceder a las preferencias del usuario y acceder al token para utilizar el comando 'oc'.
- Botón para mostrar/ocultar menús: Muestra y oculta los menús y selección de vista de la pantalla.
- Botón inicio: Vuelve a la página de inicio de OpenShift.
- App Launcher: Enlaces a otras aplicaciones externas a OpenShift (por ejemplo, GitLab, ArgoCD, etc.).
- Botón Import file: permite importar un fichero YAML en OpenShift.
- Menú Ayuda: Guías y documentación oficial de OpenShift.
IMPORTANTE: Para poder visualizar correctamente los menús o submenús de OpenShift, habrá que elegir un proyecto al inicio (vista Administrator) o seleccionarlo desde el desplegable de la página principal del menú/submenú (vista Developer). Si no se elige un proyecto, no se podrá visualizar los recursos de este (Pipelines, Workloads, etc.), y aunque aparezcan los menús, y naveguemos hasta cualquiera de las opciones, no mostrará nada.

Obtención del Token para la línea de comandos
Para poder utilizar la línea de comandos desde local, hay que conectarse a OpenShift utilizando un cliente (OC) y realizar la autenticación vía token. Adicionalmente, se tendrá que tener visibilidad con la API del entorno a utilizar (publicada en puerto no estándar 6443). Para obtener el comando a utilizar, ir al Menú del usuario (ver "Figura 3. Página inicial de OpenShift de un Administrador" punto 4) y seleccionar la opción "copy login command".
Esto abrirá una ventana que solicitará nuevamente las credenciales (seguir los mismos pasos que para iniciar sesión en OpenShift). Una vez dentro, aparecerá una página en blanco con el enlace Display Token.

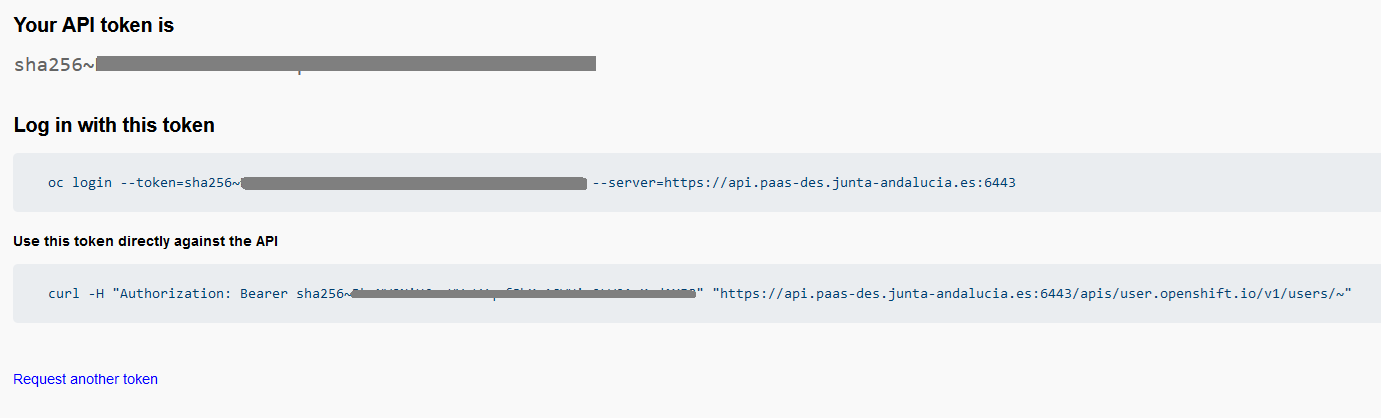
Pulsar en el enlace "Display Token" se mostrará el token, así como el comando para poder acceder por línea de comandos y una petición curl para utilizar la API. Al final de la página, aparecerá un enlace para solicitar otro token en caso de que haya caducado el actual.
El comando del login sería:
oc login -token=sha256~<TOKEN_USUARIO> --server=<URL>
Y el del curl :
curl -H "Authorization: Bearer sha256~<TOKEN_USUARIO>" "<URL>/apis/user.openshift.io/v1/users/~"
Donde <TOKEN_USUARIO> sería el Token que aparece en "Your API token is" y <URL> la URL del entorno donde esta OpenShift.
El cliente de "oc" se puede descargar desde la propia plataforma, para ello hay que acceder al menú de ayuda y seleccionar Command Line Tools.

En la página de descargas, el cliente estará disponible para múltiples plataformas.
Vistas de OpenShift
OpenShift dispone de dos vistas según el rol del usuario registrado, estas son Administrator y Developer. La estructura de cada vista es la misma, salvo que el rol Administrator permitirá acceder a más opciones que el de Developer. Por último, un usuario con el rol Administrator puede cambiar de vista a Developer y viceversa, pero un usuario Developer solo tendrá disponible la vista propia de su rol.
Para cambiar de vista hay que dirigirse al botón vista del usuario que se encuentra a la izquierda de la pantalla encima de los menús (ver "Figura 3. Página inicial de OpenShift de un Administrador" punto 1). Desplegar el menú y seleccionar el rol al que deseemos cambiar.
Por ejemplo, si cambiamos a la vista para un Developer, mostrará una página similar a la "Figura 12. Página inicial de OpenShift de un Developer".
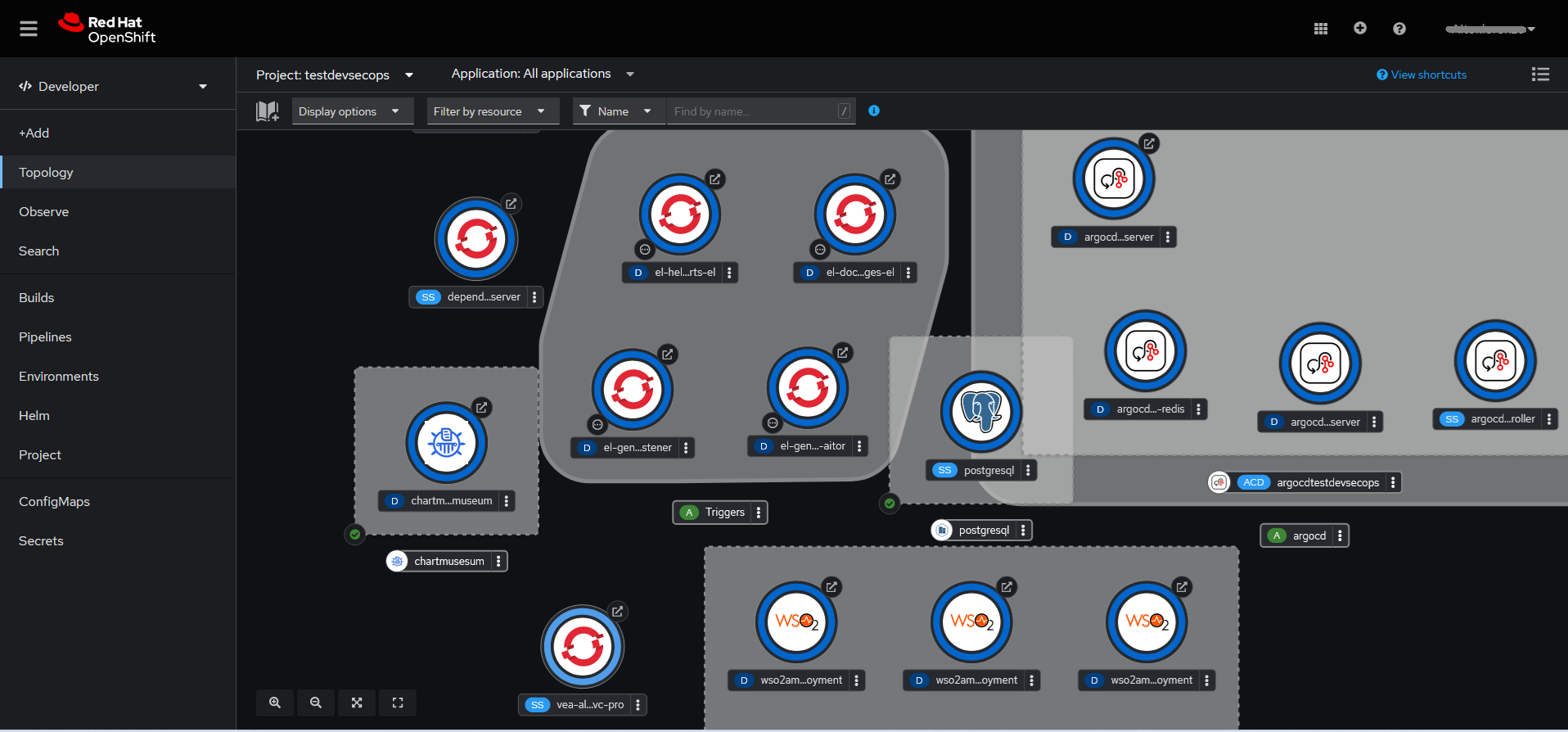
Creación de recursos en OpenShift
Los recursos de OpenShift se definen en ficheros YAML. Estos incluyen instrucciones que especifican a la plataforma como tiene que crear un determinado recurso. Se pueden escribir en un fichero de texto plano o utilizando algún editor. Otra opción, es escribir el fichero dentro de la plataforma OpenShift, que ofrece una pequeña ayuda con el esquema YAML a definir. Además, si se elige esta opción para escribir el archivo, OpenShift carga una plantilla predefinida al crear recursos la cual puede utilizarse como referencia y podrá modificarse en su editor.

Esta ayuda aparece solo para la vista YAML cuando se vaya a crear un recurso de cualquier tipo en OpenShift. Es muy útil porque da una breve descripción del recurso, describe las etiquetas que permite el recurso e indica que tipo de dato es y cuál es su función. Además, si las etiquetas tienen hijos, permite navegar hacia ellos para conocer su descripción. En algunos casos habrá un enlace a la documentación oficial para explicar mejor su función.
NOTA: No es necesario definir en los YAML la etiqueta namespace (cuelga de metadata), ya que al desplegar un recurso en Openshift, este añade automáticamente dicha etiqueta con el valor del namespace donde se halla desplegado. Es un campo opcional, no es obligatorio.
metadata:
namespace: testdevsecops #(CAMPO OPCIONAL, no es obligatorio incluirlo) El namespace en el cual se crea el recurso.Configuración de Servicios y Rutas
Un servicio o Service en Kubernetes es un recurso que define un conjunto lógico de Pods y una política para acceder a ellos. Los servicios permiten el descubrimiento y la comunicación entre Pods sin importar en qué nodo estén ejecutándose.
Una Ruta o Route en OpenShift se utiliza para exponer un Servicio dentro del clúster a direcciones externas, permitiendo el acceso desde fuera del clúster.
Tanto los Servicios como las Rutas cuelgan del menú Networking en OpenShift. Para ir a cualquiera de ellos solo hay que desplegar el menú y seleccionar la opción deseada.
Servicios (Services): Cómo definir y gestionar servicios para exponer aplicaciones internamente
Tal y como se ha comentado en el apartado "Creación de recursos en OpenShift", un Servicio se define mediante un fichero YAML.
apiVersion: v1
kind: Service
metadata:
labels: #Etiqueta para identificar el servicio
name: pre-<nombre_componente>-svc #El nombre del Service. Este nombre debe ser único dentro del namespace. MPORTANTE Sustituir <nombre_componente> por el nombre real del componente.
spec:
ports: #Define los puertos que este Service expone.
- port: 443 #El puerto que publica el servicio de Kubernetes. Este es el puerto al que los clientes deben conectarse para acceder al servicio.
protocol: TCP #Protocolo utilizado (TCP)
targetPort: 8080 #El puerto en el Pod al que el tráfico se redirige. Este debe coincidir con el puerto expuesto por los contenedores definidos en el recurso de despliegue.
selector: #Define cómo seleccionar los Pods que serán gestionados por este Service.
app: pre-<nombre_componente> #Selector que coincide con la etiqueta app definida en los Pods. Este debe coincidir con el nombre de la aplicación definido en el yaml de despliegue. IMPORTANTE Sustituir <nombre_componente> por el nombre real del componente.
sessionAffinity: None #Indica que no se utilizará afinidad de sesión, es decir, las solicitudes de un mismo cliente no serán necesariamente dirigidas al mismo Pod.
type: ClusterIP #Define el tipo de Service. ClusterIP expone el servicio internamente en el clúster usando una IP interna.
Si es necesario afinidad (para una aplicación StateFul, por ejemplo), se puede utilizar:
sessionAffinity: ClientIP # Afinidad basada en IP del cliente
sessionAffinityConfig:
clientIP:
timeoutSeconds: 10800 # Duración de la afinidad (en segundos)
Una vez definido el fichero YAML podemos crear el Servicio utilizando tanto la interfaz gráfica de OpenShift, como desde la interfaz de línea de comandos.
Gestión de Servicios por interfaz gráfica
Creación: ir a la página de principal de los Servicios y pulsar "Create Service".
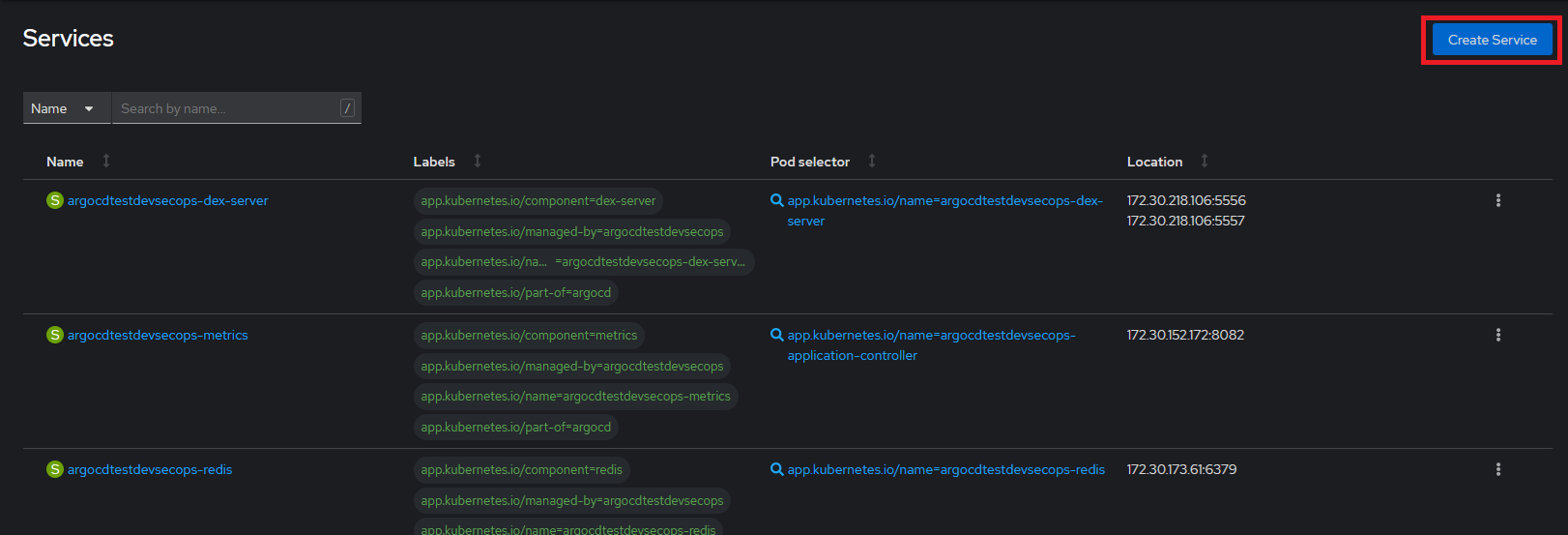
Pegar el contenido del fichero YAML en el cuadro de texto y pulsar el botón "Create".
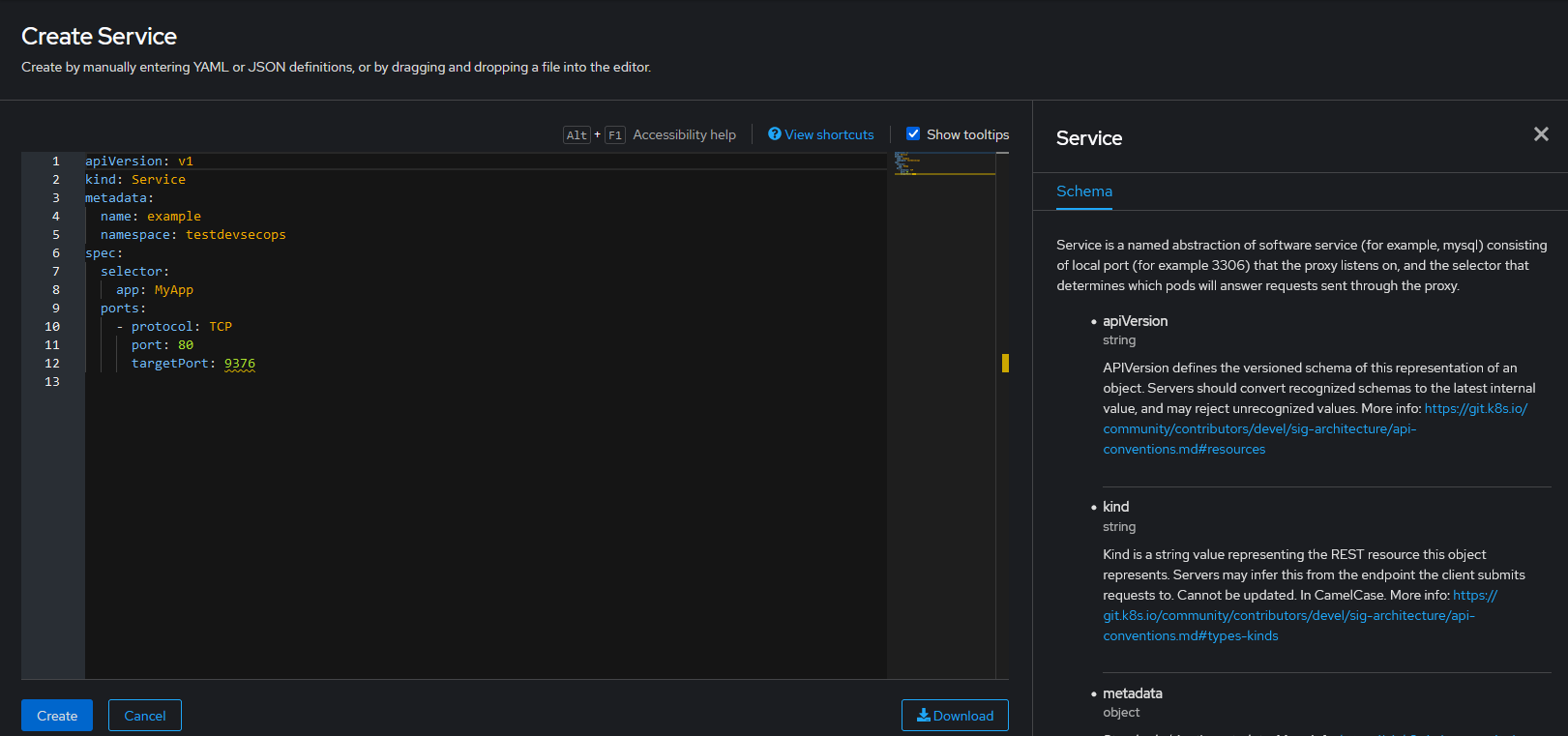
Verificación: Para comprobar que el Servicio esté creado y funcionando correctamente ir a la página principal de los Servicios y buscar el Servicio por el nombre especificado en la etiqueta name. Una vez localizado pulsar en él, e ir a la pestaña del Pod para comprobar si el estado es correcto.
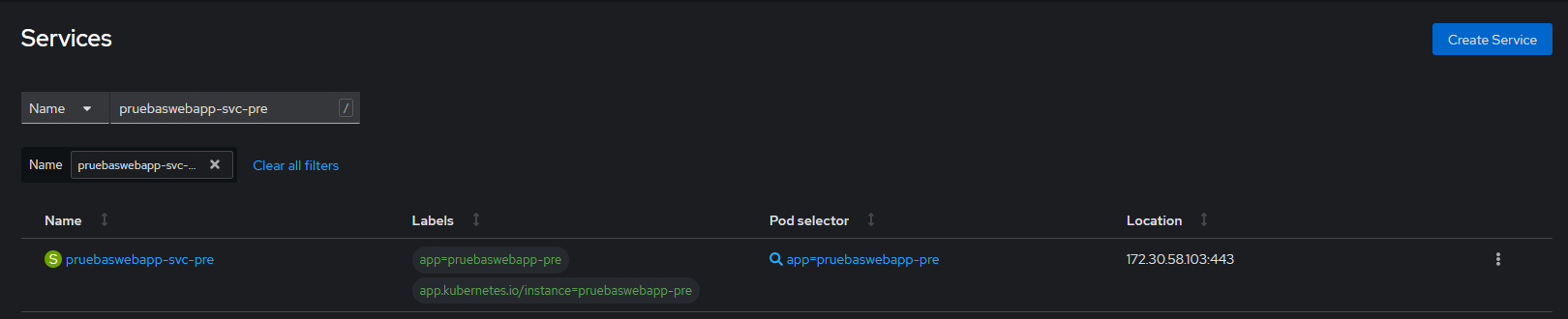
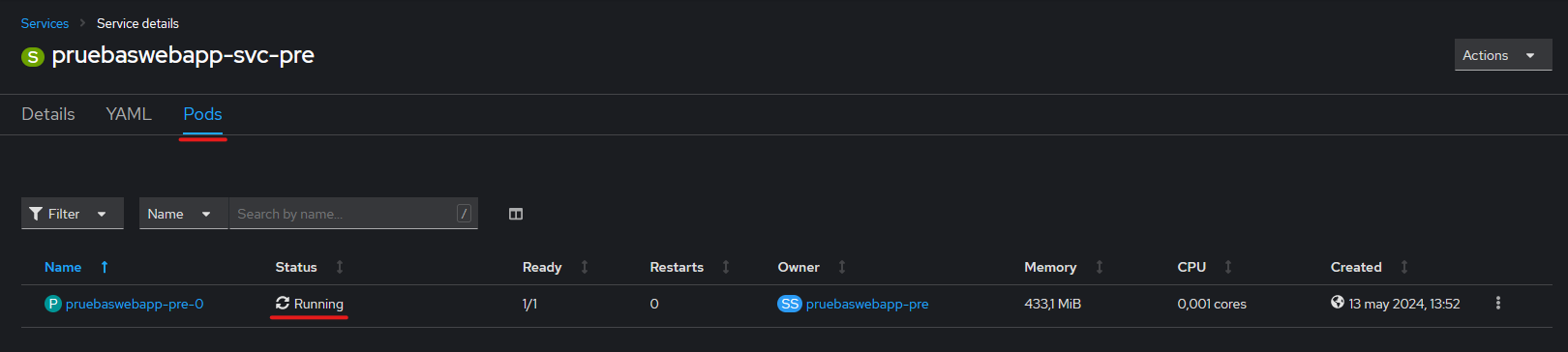
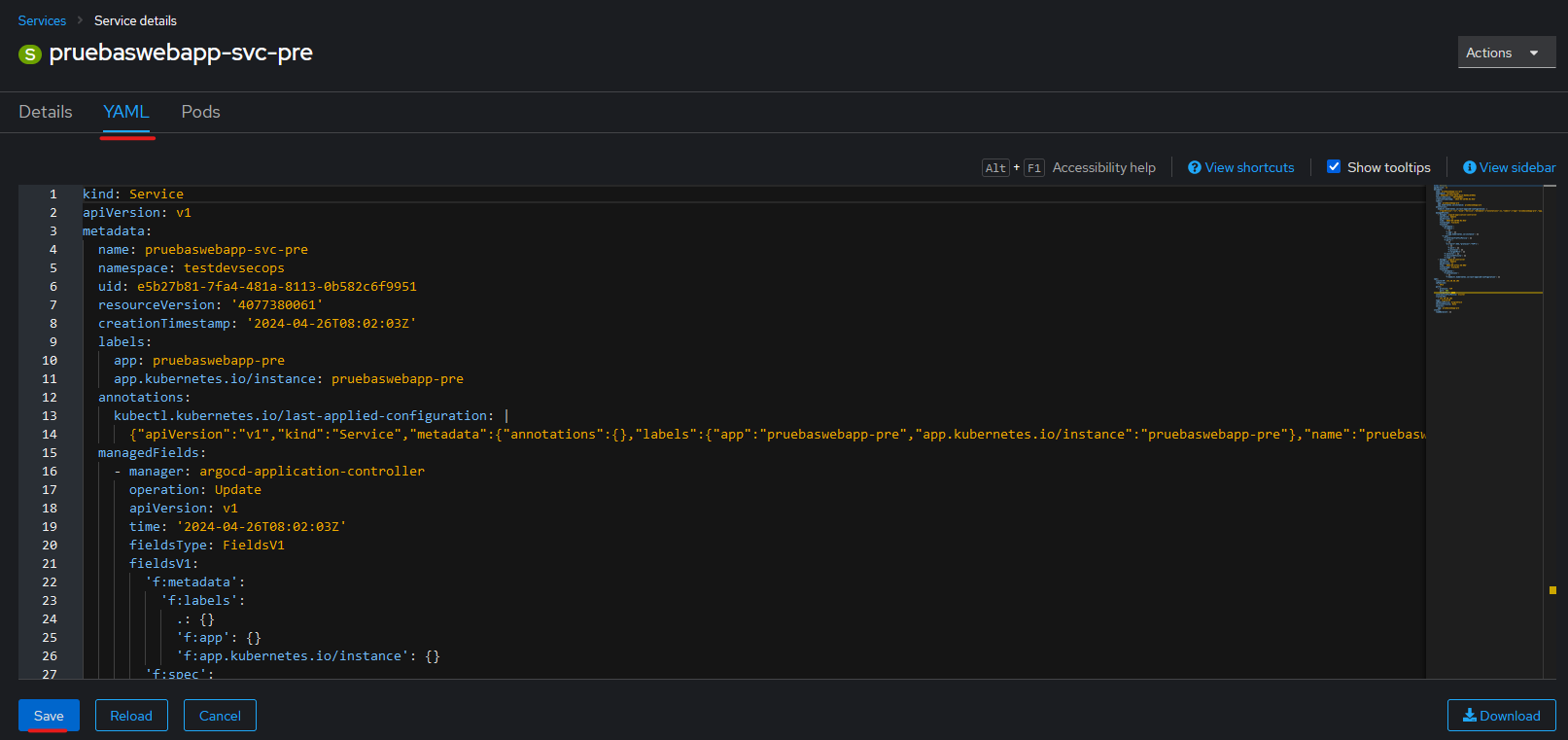
Actualización: Para actualizar un Servicio, pulsar en la pestaña YAML, y de esta forma accedemos al editor online. Modificamos el YAML y pulsamos el botón "Save".
Eliminación: Para eliminar el Servicio ir al desplegable de arriba a la derecha en la página del Servicio, y pulsar la opción "Delete Service".

Gestión de Servicios por línea de comandos
Creación: Aplicar el archivo YAML utilizando el comando:
oc apply -f pruebaswebapp-svc.yaml -n testdevsecopsEs posible obviar el uso de -n testdevsecops, seleccionando primero el proyecto:
oc project testdevsecopsPara el resto de ejemplos, asumiremos que se ha seleccionado el proyecto, por lo que los recursos se crearán en el proyecto seleccionado (si no se especifica el namespace en la propia definición del recurso).
Verificación: Verificar que el Servicio esté creado y funcionando correctamente usando:
oc get servicesActualización: Para actualizar el Servicio, modificar el archivo YAML y aplicar los cambios nuevamente con:
oc apply -f pruebaswebapp-svc.yamlEliminación: Eliminar el Servicio con:
oc delete service pruebaswebapp-svc-pre -
Rutas (Routes): Cómo crear rutas para exponer servicios externamente
Tal y como se ha comentado en el apartado "Creación de recursos en OpenShift", una Ruta se define mediante un fichero YAML.
apiVersion: route.openshift.io/v1 #Indica la versión de la API de OpenShift que se está utilizando para definir el recurso. route.openshift.io/v1 es la versión estable para Routes.
kind: Route #Especifica el tipo de recurso que se está definiendo, en este caso, una Route.
metadata:
name: pre--<nombre_componente>-route #El nombre de la Route. IMPORTANTE Sustituir <nombre_componente> por el nombre real del componente.
labels: #Etiquetas para identificar la ruta
app: pre-<nombre_componente> # IMPORTANTE Sustituir <nombre_componente> por el nombre real del componente.
spec:
host: <nombre_componente>-route-pre.apps.paas-des.junta-andalucia.es #El host o URL externa que se utilizará para acceder al servicio. Este nombre debe ser único y es la dirección que los usuarios utilizarán para acceder a la aplicación. Hasta <nombre_componente>-route-pre, es configurable por el usuario. IMPORTANTE: Esta parte apps.paas-des.junta-andalucia.es es fija del dominio (que variaría en cada cluster).
to:
kind: Service #Especifica que el destino de la Route es un Service.
name: pruebaswebapp-svc-pre #El nombre del Service al que se enruta el tráfico.
weight: 100 #El peso de la ruta cuando se utilizan múltiples servicios de destino para balanceo de carga.
port:
targetPort: 8080 #El puerto del servicio al que se redirige el tráfico. En este caso, el tráfico se dirige al puerto 8080 del servicio pruebaswebapp-svc-pre.
tls:
termination: edge #Indica que se utilizará terminación TLS en el borde (edge), lo que significa que la conexión segura se termina en el balanceador de carga y el tráfico hacia el Pod será sin cifrar.
wildcardPolicy: None #Indica la política de comodines. None significa que no se permiten subdominios comodín para esta ruta. name: main-servicekind: Routemetadata: name: secondary-routespec: host: "*.example.com" to: kind: Service
A continuación se explican otros valores para algunas de las etiquetas de la ruta.
Host:
Dado que existen 4 clústers, tal y como se indica en el punto 2, la parte inmutable del host varia según estos, por ejemplo:
- ZOCO_DES: <route_del_componente>.apps.paas-des.junta-andalucia.es
- ZOCO_PRO: <route_del_componente>.apps.paas-pro.junta-andalucia.es
- CICA_DES: <route_del_componente>.apps.paas-des-cica.junta-andalucia.es
- CICA_PRO: <route_del_componente>.apps.paas-pro-cica.junta-andalucia.es
termination:
spec:
...
tls:
termination: edgeValores de la etiqueta:
edge: Indica que se utilizará terminación TLS en el borde (edge), lo que significa que la conexión segura se termina en el balanceador de carga y el tráfico hacia el Pod será sin cifrar.
passthrough: La terminación de TLS se realiza directamente en los Pods del backend, lo que significa que el balanceador de OpenShift transfiere el tráfico TLS cifrado a los Pods sin modificarlo. Adecuado para aplicaciones que necesitan cifrado TLS tanto para el tráfico externo como interno, ya que el cifrado se mantiene desde el cliente hasta el backend.
reencrypt: La terminación de TLS se realiza en el balanceador de OpenShift, pero luego se vuelve a cifrar antes de enviarlo al backend del servicio.
wildcardPolicy:
spec:
...
wildcardPolicy: None #Indica la política de comodines. None significa que no se permiten subdominios comodín para esta ruta.Valores posibles de la etiqueta:
None: Significa que no se permiten subdominios comodín para esta ruta.
Subdomain: Permite el uso de comodines para los subdominios. Cualquier subdominio que coincida con la parte izquierda de la especificación de la ruta será enrutado a la ruta definida. Útil cuando se desea capturar y enrutar dinámicamente todos los subdominios bajo un dominio específico a una ruta, sin tener que definir explícitamente cada subdominio.
NoneOverwrite: Similar a None, pero permite que esta configuración sea sobrescrita por reglas de ruta secundarias. Por ejemplo, tenemos una ruta:
apiVersion: route.openshift.io/v1 kind: Route metadata: name: main-route spec: host: example.com to: kind: Service name: main-service wildcardPolicy: NoneOverwriteY otra definida como:
apiVersion: route.openshift.io/v1 kind: Route metadata: name: secondary-route spec: host: "*.example.com" to: kind: Service name: secondary-service wildcardPolicy: SubdomainEn este caso, la ruta secundaria secondary-route permitirá el uso de comodines para los subdominios. Si se accediera a la ruta con http://example.com, accederíamos a main-service y si accediéramos a http://test.example.com a secondary-service.
Una vez definido el fichero YAML podemos crear la Ruta utilizando tanto la interfaz gráfica de OpenShift, como la línea de comandos.
Gestión de Rutas por interfaz gráfica
Creación: ir a la página principal de las Rutas y pulsar el botón "Create Route".

Pegar el contenido del fichero YAML en el cuadro de texto y pulsar el botón "Create".
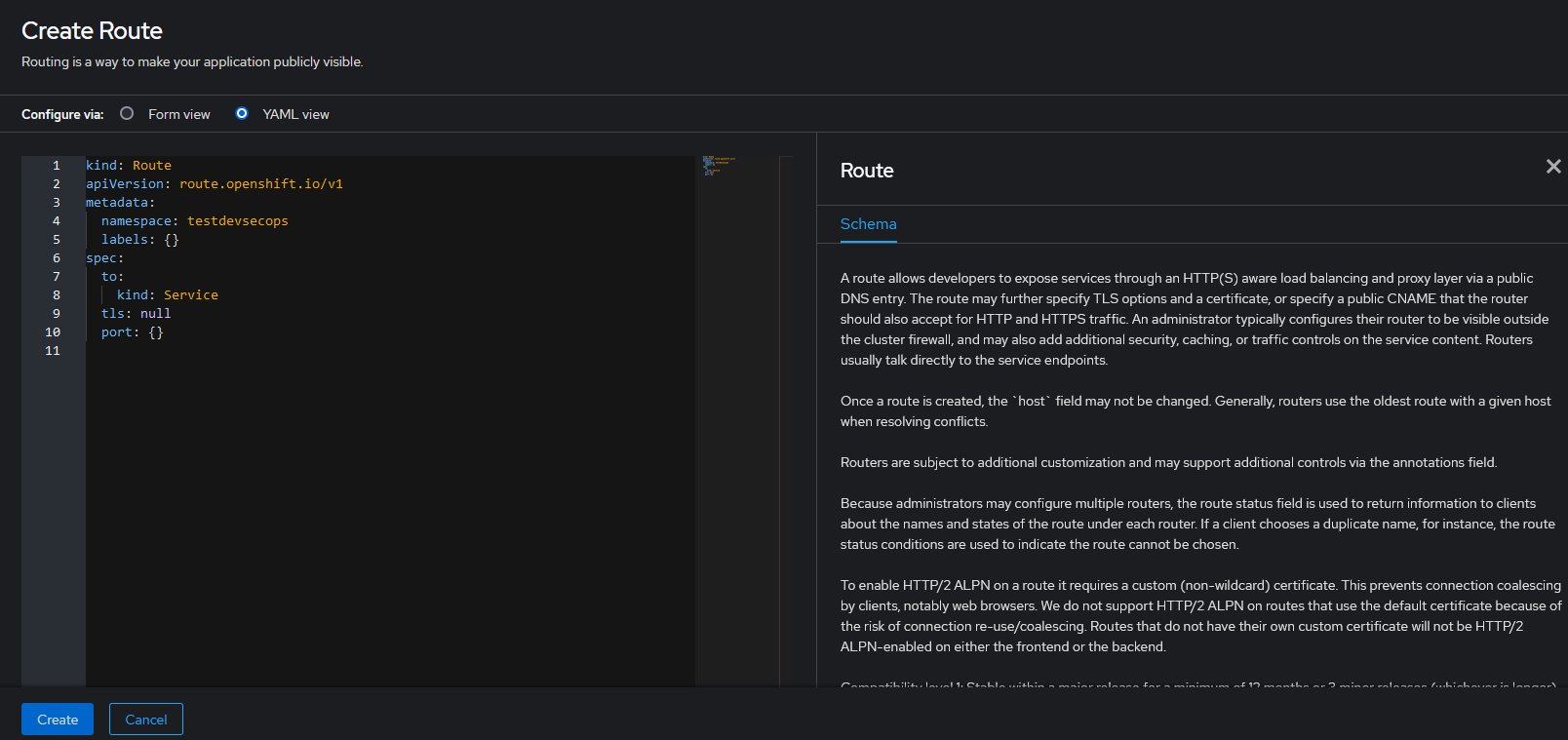
Verificación: Para comprobar que la Ruta se haya creado correctamente ir a la página principal de las Rutas y buscar la Ruta por el nombre especificado en la etiqueta name. Una vez localizada verificar que el estado es correcto.

Actualización: Para actualizar una Ruta, pulsar la pestaña YAML, de esta forma accedemos al editor online. Modificamos el YAML y pulsamos el botón "Save".
Eliminación: Para eliminar una Ruta ir al desplegable de arriba a la derecha en la página de la Ruta, y pulsar la opción "Delete Route".

Gestión de Rutas por línea de comandos
Creación: Aplicar el archivo YAML utilizando el comando:
oc apply -f pruebaswebapp-route.yaml -n testdevsecopsVerificación: Verificar que la Ruta esté creada y funcionando correctamente usando:
oc get routesActualización: Para actualizar la Ruta, modificar el archivo YAML y aplicar los cambios nuevamente con:
oc apply -f pruebaswebapp-route.yamlEliminación: Eliminar la Ruta con:
oc delete route pruebaswebapp-route-pre
Configuración de ConfigMaps y Secrets
Los ConfigMaps en Kubernetes son una herramienta para gestionar la configuración de aplicaciones de manera flexible y portable. Permiten separar la configuración del código de la aplicación, lo que facilita la gestión y el despliegue en diferentes entornos. La creación, actualización y eliminación de ConfigMaps es sencilla y se realiza mediante archivos YAML y comandos kubectl u oc. Los ConfigMaps se pueden usar como variables de entorno o como volúmenes montados, proporcionando una gran versatilidad en la forma en que se aplican las configuraciones en los contenedores.
Los Secrets o Secretos en Kubernetes son esenciales para gestionar información sensible de manera segura. Permiten almacenar y manejar datos críticos como contraseñas, tokens y claves SSH, separándolos de la configuración de la aplicación.
Los Sealed Secrets en Kubernetes proporcionan una manera segura de gestionar y versionar información sensible. Los secretos son cifrados con una clave pública y solo pueden ser descifrados por el controlador de Sealed Secrets en el clúster, lo que permite su almacenamiento seguro en repositorios de control de versiones. OpenShift no ofrece de manera nativa Selead Secret, es un agregado que se le ha añadido a cada uno de los clústeres.
Tanto los ConfigMap como los Secret cuelgan del menú Workloads en OpenShift. Para ir a cualquiera de ellos solo hay que desplegar dicho menú y seleccionar la opción deseada.
ConfigMaps: Creación y uso de ConfigMaps para almacenar configuraciones
Tal y como se ha comentado en el apartado "Creación de recursos en OpenShift", un ConfigMap se define mediante un fichero YAML. Se puede crear el
Ejemplo:
apiVersion: v1 #Indica la versión de la API que se está utilizando para definir el recurso. En este caso, v1 es la versión estable para ConfigMaps.
kind: ConfigMap #Especifica el tipo de recurso que se está definiendo. Aquí, es un ConfigMap.
metadata: #Esta sección contiene metadatos que identifican el ConfigMap.
name: pre-<nombre_componente>-configmap #El nombre del ConfigMap. Este nombre debe ser único dentro del namespace. IMPORTANTE Sustituir <nombre_componente> por el nombre real del componente.
data: #Contiene los datos de configuración como pares clave-valor que se almacenan en el ConfigMap.
CONFIGMAPJAVA_TOOL_OPTIONS: |-
-Dlogging.path=/opt/logs/
-Dspring.application.name=<nombre_componente>
-XX:MaxRAMPercentage=75.0
-Duser.timezone=Europe/Madrid
-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=0.0.0.0:8787 #Clave llamada JAVA_TOOL_OPTIONS con el valor indicado. IMPORTANTE: Esto es un ejemplo, no se debe copiar tal cual
puerto: "8080" #Clave llamada puerto con el valor "8080".
logging_level_root: "INFO" #Clave llamada logging_level_root con el valor "INFO".En el apartado "Montaje de ConfigMaps y Secrets" se incluye un ejemplo de inclusión de un fichero de configuración definido en un ConfigMap.
Al igual que el resto de recursos de Kubernetes, una vez definido el fichero YAML se puede crear el ConfigMap utilizando tanto la interfaz gráfica de OpenShift, como la línea de comandos. Pero también existe la posibilidad de crear y desplegar con un solo comando el ConfigMap, esto es útil para incluir la información de ficheros externos.
Creación de un ConfigMap por línea comando a través de un fichero de configuración
La creación de un ConfigMap por línea de comandos permite crear el YAML automáticamente, sin tener que definirlo de forma manual, y, además, puede inyectar el contenido de uno o varios ficheros, como por ejemplo archivos de configuración de una aplicación.
Para poder crear el ConfigMap por línea de comandos primero hay que conectarse con OpenShift mediante una autenticación con Token. Este proceso esta detallado en el apartado "Obtención del Token para la línea de comandos".
Una vez conectados podemos crear un ConfigMap básico con el comando:
oc create configmap <nombre_recurso> -n testdevsecopsEsto creará un ConfigMap en el proyecto al que estemos conectados en el clúster.
Como se puede observar en la imagen anterior se ha creado un ConfigMap llamado pruebaswebapp-configmap en el proyecto testdevsecops, pero sin la etiqueta data. Habría que modificar el ConfigMap y añadir los datos de configuración manualmente si fuera necesario.
Pero como se ha comentado anteriormente también se puede crear el ConfigMap inyectando parámetros de configuración automáticamente desde un fichero o ficheros externos. Esto se puede lograr de dos formas con las etiquetas:
- --from-file: Permite inyectar un fichero en el ConfigMap. Se puede incluir la etiqueta varias veces según el número de ficheros a inyectar o un directorio con todo su contenido.
oc create configmap <nombre_recurso> --from-file=<path_al_fichero> [--from-file=<path_al_fichero>]Por ejemplo, tenemos un directorio llamado "config" con los ficheros:
- app.properties
port=4099 logs=ERROR autostart=true db=TYPE_DB db.url=URL_DB db.credentials.user=user db.credentials.pass=pass
- ui.properties
color.back=purple color.font=yellow allow.textmode=truePara crear el ConfigMap, situarse en la ruta del directorio "config" y lanzar el siguiente comando:
oc create configmap pruebaswebapp-configmap --from-file=configO indicar ruta absoluta en --from-file:
oc create configmap pruebaswebapp-configmap --from-file=/config/*ui.properties --from-file=/config/app.propertiesEsto creará el siguiente ConfigMap:
apiVersion: v1 kind: ConfigMap metadata: creationTimestamp: "2024-06-18T08:34:00Z" name: pruebaswebapp-configmap namespace: testdevsecops resourceVersion: "4264774898" uid: aa8dcf4f-8d91-4f31-a66f-d7a2970a8916 data: app.properties: | port=4099 logs=ERROR autostart=true db=TYPE_DB db.url=URL_DB db.credentials.user=user db.credentials.pass=pass ui.properties: | color.back=purple color.font=yellow allow.textmode=trueTal y como se puede observar se ha creado un ConfigMap con la etiqueta data de la que cuelgan otras dos etiquetas que coinciden con el nombre de los archivos inyectados. De cada una de ellas cuelga el contenido su propio fichero.
Se puede también establecer un alias al fichero inyectado con el parámetro --from-file=<my-key-name>=<path-to-file>
oc create configmap pruebaswebapp-configmap --from-file=ui=ui.properties --from-file=app=app.propertiesDe esta forma en vez de aparecer los nombres de fichero en el Configmap, pondría el alias indicado en el comando:
data: app: | port=4099 logs=ERROR autostart=true db=TYPE_DB db.url=URL_DB db.credentials.user=user db.credentials.pass=pass ui: | color.back=purple color.font=yellow allow.textmode=true
- --from-env-file: Permite crear un ConfigMap con la información de un fichero de configuración de variables de entorno. Se puede incluir la etiqueta varias veces según el número de ficheros a inyectar o un directorio con todo su contenido.
oc create configmap <nombre_recurso> --from-env-file=<path_al_fichero> [--from-env-file=<path_al_fichero>]Por ejemplo, tenemos el siguiente directorio llamado "config" con los ficheros:
- app-env-file.properties
autorestart=true path=/path autostart=1GB VAR_HOME=/var/bin
- ui-env-file.properties
admin=false textmode=truePara crear el ConfigMap situarse en el directorio "config" y lanzar el siguiente comando:
oc create configmap pruebaswebapp-configmap --from-env-file=configO establecer la ruta absoluta en --from-env-file:
oc create configmap pruebaswebapp-configmap --from-env-file=/config/ui-env-file.properties --from-env-file=/config/app-env-file.propertiesEsto creará el siguiente ConfigMap:
apiVersion: v1 kind: ConfigMap metadata: creationTimestamp: "2024-06-18T09:00:03Z" name: pruebaswebapp-configmap namespace: testdevsecops resourceVersion: "4264838197" uid: edbcef99-5ab9-4644-9c94-cba9ef9b97ed data: VAR_HOME: /var/bin admin: "false" autorestart: "true" maxmem: 1GB path: /path textmode: "true"En este caso crea el ConfigMap con la etiqueta "data" con la fusión del contenido de los dos ficheros.
Otra opción sería forzar a que cree un YAML con la información del ConfigMap en local, para después cargarlo en OpenShift con alguna de las opciones indicadas en los apartados "Gestión de ConfigMaps por interfaz gráfica" o "Gestión de ConfigMaps por línea de comandos".
Esto se logra añadiendo al final del comando utilizado los parámetros:
--dry-run=client -o yaml > <nombre_fichero>--dry-run=client: muestra una vista previa del objeto a crear.
-o yaml: muestra el objeto en formato YAML.
<nombre_fichero> vuelva a un fichero local la ejecución del comando.
Ejemplo:
oc create configmap pruebaswebapp-configmap --from-file=config --dry-run=client -o yaml > pruebaswebapp-configmap.yamlCrearía un fichero llamado pruebaswebapp-configmap.yaml con la información de los ficheros incluidos en el directorio "config".
apiVersion: v1
kind: ConfigMap
metadata:
creationTimestamp: null
name: pruebaswebapp-configmap
data:
app.properties: |
port=4099
logs=PATH
autostart=true
db=TYPE_DB
db.url=URL_DB
db.credentials.user=user
db.credentials.pass=pass
ui.properties: |
color.back=purple
color.font=yellow
allow.textmode=true Más información sobre creación de ConfigMap en el siguiente enlace:
https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/
Gestión de ConfigMaps por interfaz gráfica
Creación: ir a la página principal de los ConfigMaps y pulsar el botón "Create ConfigMap".
Pegar el contenido del fichero YAML en el cuadro de texto y pulsar el botón "Create".
Verificación: Para comprobar que el ConfigMap esté creado, ir a la página de los ConfigMaps y buscarlo por el nombre especificado en la etiqueta name.

Actualización: Para actualizar un ConfigMap, ir a la página del ConfigMap correspondiente y pulsar en la pestaña YAML. De esta forma accedemos al editor online, modificamos el YAML y pulsamos el botón "Save".
Eliminación: Para eliminar un ConfigMap ir al desplegable de arriba a la derecha en la página del ConfigMap, y pulsar la opción "Delete ConfigMap".

Gestión de ConfigMaps por línea de comandos
Creación: Aplicar el archivo YAML utilizando el comando:
oc apply -f pruebaswebapp-configmap.yaml -n testdevsecopsVerificación: Verificar que la ruta esté creada y funcionando correctamente usando:
oc get configmapsActualización: Para actualizar la ruta, modificar el archivo YAML y aplicar los cambios nuevamente con:
oc apply -f pruebaswebapp-configmap .yamlEliminación: Eliminar la ruta con:
oc delete configmaps pruebaswebapp-configmap-preSecrets: Creación y gestión de Secrets para almacenar información sensible
Tal y como se ha comentado en el apartado "Creación de recursos en OpenShift", un Secreto se define mediante un fichero YAML.
Ejemplo:
apiVersion: v1 #Indica la versión de la API de Kubernetes que se está utilizando para definir el recurso. v1 es la versión estable para Secrets.
kind: Secret #Especifica el tipo de recurso que se está definiendo, en este caso, un Secret.
metadata:
name: pre-<nombre_componente>-secret #Nombre del secreto. IMPORTANTE Sustituir <nombre_componente> por el nombre real del componente.
labels:
app: pre-<nombre_componente> #Etiqueta para identificar el Secret. Esto puede ser útil para la organización y selección de recursos dentro del clúster.
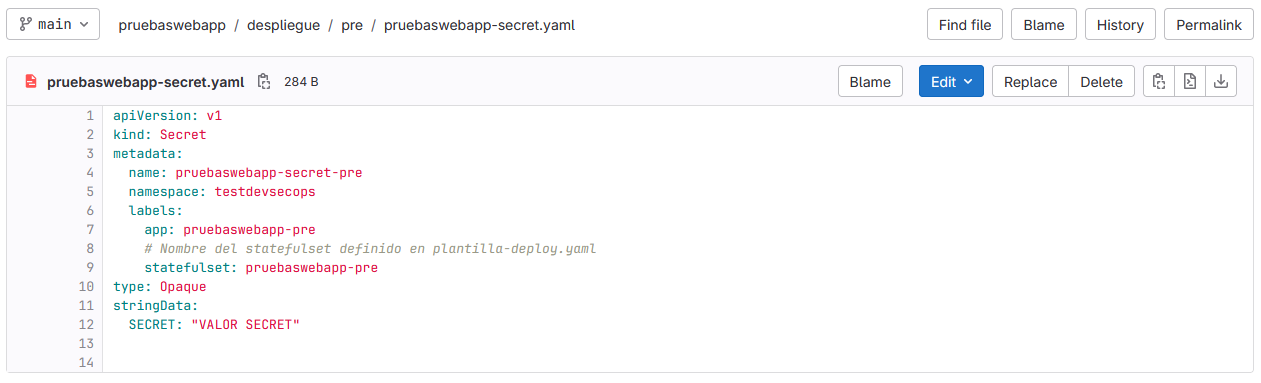
statefulset: pre-<nombre_componente>-deploy #Etiqueta adicional para asociar el Secret con un StatefulSet específico. IMPORTANTE: Si en vez de un statefulSet se utiliza un deployment cambiar el nombre de la etiqueta.
type: Opaque #Define el tipo de Secret. Opaque es el tipo genérico utilizado para almacenar datos arbitrarios como pares clave-valor.
data: #Contiene los datos sensibles que se almacenan en el Secret. Los datos se especifican como cadenas de texto codificadas en base64, a diferencia del campo stringData que no se condifica.
USER: YWRhLmltcHVsc29kZXZzZWNvcHM= #Una clave llamada USER con el valor "YWRhLmltcHVsc29kZXZzZWNvcHM=". Este valor se almacenará como un secreto y puede ser utilizado por los Pods que necesiten esta información.Los Secretos contienen dos mapas, Data y stringData, ambos deben estar compuestos por caracteres alfanuméricos, '-', '_' o '.':
Data: Se utiliza para almacenar datos arbitrarios y estos deben estar codificados en Base64.
data:
username: YWRtaW4=
password: MWYyZDFlMmU2N2RmstringData: Se utiliza para almacenar cadenas de texto sin codificar. Todas las claves y valores se fusionan en un solo dato. Cuando se cree o se modifique el Secreto, este campo será codificado en Base64.
stringData:
config.yaml: |
apiUrl: "https://my.api.com/api/v1\"
username: <user>
password: <password>type: Indica el tipo de Secreto, Opaque es el tipo genérico utilizado para almacenar datos arbitrarios como pares clave-valor. Kubernetes facilita varios tipos para según que escenarios. Más información en el siguiente enlace:
https://kubernetes.io/docs/concepts/configuration/secret/#secret-types
Una vez definido el fichero YAML podemos crear el Secreto utilizando tanto la interfaz gráfica de OpenShift, como la línea de comandos.
Gestión de Secretos por interfaz gráfica
Creación: ir a la página principal de los Secretos y desplegar el botón "Create" Y seleccionar "From YAML".

Pegar el contenido del fichero YAML en el cuadro de texto y pulsar el botón "Create".
Verificación: Para comprobar que el Secreto esté creado, ir a la página principal de los Secretos y buscarlo por el nombre especificado en la etiqueta name.

Actualización: Para actualizar un Secreto, ir a la página del Secreto correspondiente y pulsar en la pestaña YAML. De esta forma accedemos al editor online, modificamos el YAML y pulsamos el botón "Save".
Eliminación: Para eliminar un Secreto ir al desplegable de arriba a la derecha en la página del Secreto, y pulsar la opción "Delete Secret".

Gestión de Secretos por línea de comandos
Creación: Aplicar el archivo YAML utilizando el comando:
oc apply -f pruebaswebapp-secret.yaml -n testdevsecopsVerificación: Verificar que la ruta esté creada y funcionando correctamente usando:
oc get secrets -n testdevsecopsActualización: Para actualizar la ruta, modificar el archivo YAML y aplicar los cambios nuevamente con:
oc apply -f pruebaswebapp-secret.yamlDecodificación: Para decodificar los datos, usar:
oc get secrets pruebaswebapp-secret-pre -o jsonpath="{.data.SECRET}" | base64 --decodeEliminación: Eliminar la ruta con:
oc delete secrets pruebaswebapp-secret-preSealed Secret: Solicitud de cifrado
Aunque los Secretos sean útiles para gestionar información sensible, no son del todo seguros ya que solo se codifican en Base64 y cualquier usuario con acceso al secreto puede ver su contenido. En cambio, los Sealed Secret permiten cifrar la información de los Secretos para ofrecer una solución más segura.
El equipo de Operaciones es el encargado de cifrar los secretos para los entornos PRE y PRO. Para la solicitud exclusiva en esto entornos, habrá que proceder de la siguiente forma:
- Crear el Secreto. El secreto NO cifrado, no se subirá a GitLab a menos que el equipo de desarrollo considere que no es crítico ni impacta en la seguridad tener información sensible en el repositorio. (ver apartados "Secrets: Creación y gestión de Secrets para almacenar información sensible").
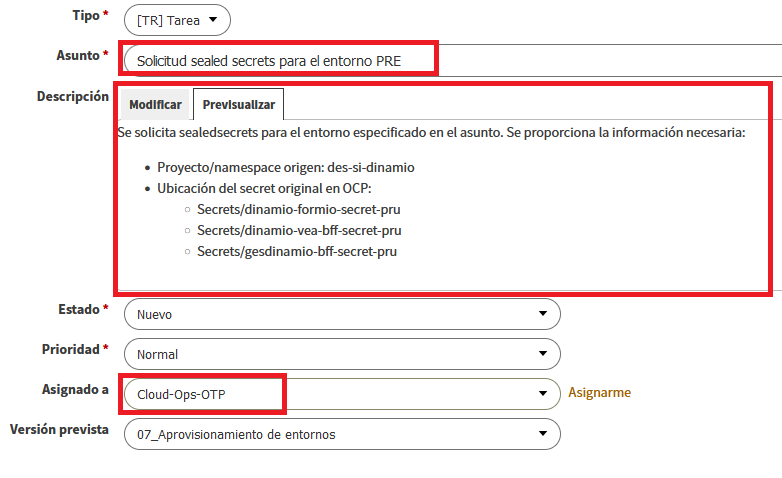
- Una vez creado el Secreto, hay que solicitar via TEO la creación del Sealed Secret, para ello crear una subtarea dentro de la tarea de "Aprovisionamiento de entornos" en el proyecto, con la siguiente estructura:
Asunto: Solicitud sealed secrets para el entorno <especificar_entorno>
Descripción: Se solicita sealed secrets para el entorno especificado en el asunto. Se proporciona la información necesaria:
Proyecto/namespace origen: <especificar_namespace>
Ubicación del secret original en OCP:
Secrets/<nombre_fichero_1>
....
Secrets/<nombre_fichero_n>
Ejemplo con datos reales:
Asunto: Solicitud sealed secrets para el entorno PRE
Descripción: Se solicita sealed secrets para el entorno especificado en el asunto. Se proporciona la información necesaria:
Proyecto/namespace origen: des-si-dinamio
Ubicación del secret original en OCP:
Secrets/dinamio-formio-secret-test
Secrets/dinamio-vea-bff-secret-test
Secrets/gesdinamio-bff-secret-test
Una vez introducidos los datos en el asunto y la descripción hay que asignársela al equipo de Operaciones, para ello hay que desplegar el campo "Asignado a" y seleccionar Cloud-Ops-PEC.
- El equipo de Operaciones accedería a OCP y obtendría los ficheros especificados del namespace, cifrará los Secretos convirtiéndolos en Sealed Secrets.
- Una vez cifrado, el equipo de Operaciones subiría a TEO los ficheros cifrados, comentará en la tarea que ya se ha cifrado y la reasignará a la persona o grupo que la creó.
- Por último, el equipo de desarrollo subirá el secreto cifrado al repositorio.
Importante: el fichero con el sealed secret entregado por Operaciones no debe modificarse su contenido, si se modifica fallaría el despliegue de dicho secreto.
Volúmenes y Almacenamiento Persistente
Los contendedores no tienen persistencia, esto quiere decir, que cuando se destruye el contenedor, todos los datos que tuviese, también son eliminados. Para evitar la pérdida de datos, se pueden utilizar volúmenes. Estos proporcionan un mecanismo que conecta los contenedores con sistemas de archivo persistentes, que pueden estar conectados al host local o a la red.
OpenShift utiliza los PV (PersistentVolume) de Kubernetes para permitir a los administradores aprovisionar persistencia de datos en el clúster. Por otra parte, los desarrolladores pueden usar los PVC (Persistent Volume Claims) para pedir a los PV recursos de almacenamiento, de esta forma no necesitan conocer la estructura de almacenamiento subyacente.
Tipos de volúmenes
OpenShift soporta diferentes tipos de PV, ya sean nativos o mediante plugins. El soportado actualmente por la instancia instalada en PreCloud es OpenShift Container Storage 4.
OpenShift Container Storage 4 utiliza Ceph, que es una solución de código abierto para proporcionar almacenamiento a las aplicaciones. Con esta tecnología se pueden almacenar datos distribuidos en diversos recursos de la propia red, y estos pueden guardarse en diferentes soportes físicos de almacenamiento.
La base del clúster de almacenamiento es RADOS1, que es una memoria fiable y distribuida compuesta por nodos de almacenamiento inteligentes que se autorregeneran y se autoorganizan. Además, usa CRUSH2 como algoritmo que optimiza la ubicación de los datos y que es capaz de encontrar un OSD3 con el archivo solicitado gracias a una tabla de asignaciones.
Hay dos tipos de Ceph:
- RBD (RADOS Block Device): Memoria orientada a bloques a través de módulos de núcleo o sistemas virtuales. Un bloque es una secuencia de bytes, por ejemplo, un bloque de 4 MB. Las interfaces de almacenamiento basadas en bloques son la forma más habitual de almacenar datos en soportes como HDDs, SSDs, CD, o disquetes. La ubicuidad de estas interfaces hace que sean perfectas para interactuar con sistemas de almacenamiento masivo de datos como Ceph.
Los Ceph RBD permiten compartir recursos físicos y se puede modificar su tamaño. Los datos se almacenan repartidos en varios OSD en un clúster de Ceph. Los dispositivos de bloques de Ceph aprovechan las funciones de RADOS.
- FS (File System): Se trata del sistema de archivos propio de Ceph, que se ajusta al estándar POSIX, y está creado sobre el almacén de objetos distribuidos de Ceph, RADOS. Trata de proporcionar un sistema de archivos de última generación, con alta disponibilidad y rendimiento, para una variedad de aplicaciones.
Los Ceph FS permiten que los metadatos de los archivos se almacenen en un grupo RADOS separado de los datos del archivo y se sirven a través de un grupo redimensionable de MDS4 que pueden escalarse para admitir cargas de trabajo de metadatos de mayor rendimiento.
Hay que tener en cuenta el tipo de recurso que vayamos a almacenar a la hora de elegir un PVC, ya que, dependiendo del aplicativo, necesitará unos permisos u otros, o un tipo de Ceph, ya sea RBD (RADOS Block Device) o FS (File System).
| Modo de acceso | Abreviación CLI | Descripción |
|---|---|---|
| ReadWriteOnce | RWO | El volumen se puede montar como lectura-escritura para un solo nodo. |
| ReadOnlyMany | ROX | El volumen se puede montar como solo lectura para muchos nodos. |
| ReadWriteMany | RWX | El volumen se puede montar como lectura y escritura para muchos nodos. |
Tabla 1. Permisos de los PVC
Por ejemplo, si el PVC es para una Base de Datos (BD), este solo necesitará el permiso RWO y será un recurso que requerirá mayor rendimiento, por lo que se utilizará un Ceph RBD.
Para todos los PVCs que requieran un gran rendimiento se recomienda utilizar un Ceph RBD, aquí una lista de ejemplo:
Postgres
MySQL/MariaDB
MongoDB
Elasticsearch
Kafka
Esto es una recomendación directa de Red Hat.
Para todos los demás aplicativos que no necesiten un alto rendimiento o necesiten otros tipos de permisos es recomendable utilizar Ceph FS.
La elección entre RWO (ReadWriteOnce) y RWX (ReadWriteMany) estará determinada por la naturaleza y los requisitos de acceso a los datos de cada aplicación. Generalmente, se utilizará RWO para aplicaciones donde solo un único Pod necesita acceder en modo lectura/escritura al volumen (como MariaDB, PostgreSQL, ElasticSearch, Kafka, etc.). Por otro lado, RWX se prefiere para aplicaciones que requieren que múltiples Pods accedan simultáneamente en modo lectura/escritura al mismo volumen (como Apache, Nginx, WSO2, CKAN, etc.).
En caso de elegir un volumen RWO no se pueden realizar estrategias tipo RollingUpgrade, ya que hasta que no se elimine el Pod de la versión actual no se puede arrancar el Pod de la nueva versión al tener el Pod actual un bloqueo exclusivo sobre el volumen.
Mas información en el siguiente enlace:
https://cloud.redhat.com/blog/openshift-container-storage-4-introduction-to-ceph
Almacenamiento Persistente (PVC): Cómo definir los manifiestos de los PVCs
Tal y como se ha comentado en el apartado "Creación de recursos en OpenShift", un PVC se define mediante un fichero YAML.
Ejemplo:
apiVersion: v1 #Indica la versión de la API que se está utilizando para definir el recurso. En este caso, v1 es la versión estable para el PVC
kind: PersistentVolumeClaim #Especifica el tipo de recurso que se está definiendo. Aquí, es un PersistentVolumeClaim.
metadata: #Esta sección contiene metadatos que identifican el PVC.
name: PVCexample #El nombre del PCV. Este nombre debe ser único dentro del namespace.
spec: #Define las características del PVC
accessModes: #Indica el modo de acceso al recurso en este caso lectura-escritura para un nodo.
- ReadWriteOnce
volumeMode: Filesystem #Defina el tipo de volumen del PVC (Block o Filesystem).
resources: #Representa la cantidad mínima de recursos que el volumen debe tener.
requests: #Describe la cantidad mínima de recursos informáticos que el volumen tendrá.
storage: 1Gi #Especifica la capacidad de almacenamiento físico de PVC.La etiqueta accessModes permite utilizar otros valores como, por ejemplo:
ReadWriteOnce: Volumen de lectura y escritura que puede ser montado solo por un nodo. Este modo de acceso permite que varios Pods accedan al volumen si se ejecutan en el mismo nodo.
ReadOnlyMany: Volumen de solo lectura, que puede ser montado por múltiples Pods de forma simultánea en modo de solo lectura. Los Pods pueden leer datos del volumen, pero no pueden escribir en él. Útil para compartir datos de solo lectura entre múltiples Pods.
ReadWriteMany: Volumen de lectura y escritura, que puede ser montado por múltiples Pods simultáneamente, tanto en modo de lectura como de escritura. Los Pods pueden leer y escribir datos en el volumen. Útil cuando se necesita compartir datos de lectura y escritura entre múltiples Pods, como en aplicaciones que requieren acceso de escritura concurrente a un sistema de archivos compartido.
Una vez definido el fichero YAML habrá que subirlo al repositorio y solicitar su creación en OpenShift.
Para utilizar un PVC habrá que referenciarlo en el recurso que lo vaya a utilizar. Un ejemplo de esto está definido en el apartado "Montaje de volúmenes".
Solicitud de creación de PVCs.
Por problemas de rendimiento, se ha decidido que solo el equipo de Operaciones pueda crear PVCs en Openshift. Por tanto, si se necesita crear uno se realizará una petición vía TEO.
Se creará una subtarea desde la tarea de "Aprovisionamiento de entornos" con los siguientes datos:
Asunto: Solicitud de creación de PVC - [nombre_del_pvc] en [nombre_del_namespace] - [DES/PRE/PRO]
Descripción: Se solicita la creación de un PVC para el entorno especificado. Se proporciona la información necesaria:
Nombre del PVC: Nombre único para el PVC dentro del namespace.
Namespace: Namespace donde se debe crear el PVC.
Tamaño de almacenamiento: Especificad el tamaño en las correspondientes unidades (por ejemplo, 1Gi).
Modo de acceso:
ReadWriteOnce (RWO)
ReadOnlyMany (ROX)
ReadWriteMany (RWX)
Descripción del uso: Breve explicación del propósito del PVC.
Una vez introducidos los datos en el asunto y la descripción hay que asignársela al equipo de Operaciones, para ello hay que desplegar el campo "Asignado a" y seleccionar Cloud-Ops-PEC.
Nota: Sería necesario subir al repositorio el archivo manifest.yaml donde se defina este PVC, para seguir y cumplir el modelo GitOps.
Si ya se tiene preparado el manifest.yaml, debe adjuntarse al ticket o en su defecto incluir la URL del repositorio donde podemos consultarlo.
Manifiestos de Despliegue
El manifiesto de despliegue es el archivo que incluye las instrucciones que especifican a la plataforma, OpenShift en este caso, como tiene que desplegar una aplicación en uno o varios nodos en un clúster ya definido.
Tipos de Despliegues
Hay dos maneras de realizar un despliegue en OpenShift utilizando diferentes recursos u objetos de Kubernetes. Pero antes de definir los métodos de despliegue, primero hay que entender dos conceptos asociados a dichos recursos.
Aplicaciones Stateful y Stateless
La principal diferencia entre estos dos tipos de aplicaciones es que las stateless no almacenan estados o datos de la aplicación, mientras que las stateful sí que lo hacen. Por ejemplo, la parte de frontend de una aplicación web que no persiste información de sesión en la memoria del proceso sería stateless, dado que, si se reinicia la aplicación, esta no almacena ningún dato o estado previo al reinicio. Por el contrario, una aplicación stateful, podría ser una aplicación backend, que sí guarda en la memoria del proceso la sesión del usuario, perdiendo dicha información tras un reinicio. Otro ejemplo de aplicación stateful podría ser una base de datos.
Deployments y StatefulSet
Estos son los recursos de que ofrece Kubernetes para desplegar aplicaciones. Los Deployments se utilizan para aplicaciones stateless, y los Statefulset para aplicaciones stateful. Dependiendo del tipo de aplicación a desplegar se utilizará uno u otro. A continuación, se enumeran las características de cada recurso.
- Propósito y Casos de Uso
Deployment:
Diseñado para aplicaciones sin estado (stateless).
Uso para servicios web, aplicaciones backend, y cualquier aplicación donde cada réplica del Pod es intercambiable.
Permite el escalado y actualización de aplicaciones de manera simple y rápida.
StatefulSet:
Diseñado para aplicaciones con estado (stateful).
Uso para bases de datos, sistemas distribuidos, y cualquier aplicación que requiera mantener la identidad y el almacenamiento persistente de cada réplica.
Gestiona la implementación y el escalado de un conjunto de Pods, y garantiza que se mantenga una identidad única y estable para cada Pod.
- Identidad y Persistencia
Deployment:
Los Pods creados por un Deployment son idénticos e intercambiables.
No se garantiza que un Pod mantenga la misma identidad después de reinicios o reprogramaciones.
StatefulSet:
Los Pods creados por un StatefulSet tienen una identidad única y estable (nombre ordinal único).
Los nombres de los Pods y su almacenamiento persistente se mantienen constantes a través de reinicios y reprogramaciones.
- Orden de Creación y Eliminación
Deployment:
- No garantiza un orden específico para la creación o eliminación de los Pods.
StatefulSet:
Garantiza un orden específico para la creación, actualización, eliminación y escalado de los Pods.
Los Pods se crean en orden secuencial (por ejemplo, pod-0, pod-1, pod-2) y se eliminan en orden inverso.
- Almacenamiento Persistente
Deployment:
No tiene un soporte específico para volúmenes persistentes.
Si se requiere persistencia, se suele usar PersistentVolumeClaims (PVC) de forma manual y no asociada directamente con los Pods.
StatefulSet:
Proporciona un manejo nativo de volúmenes persistentes.
Cada Pod en un StatefulSet puede tener su propio PersistentVolumeClaim (PVC) asociado automáticamente, garantizando almacenamiento persistente dedicado para cada Pod.
- Escenarios de Uso Común
Deployment:
Aplicaciones web front-end (que no tengan ningún tipo de persistencia o si la tienen, que sea externa al Pod).
Aplicaciones sin estado.
Microservicios que pueden ser escalados horizontalmente sin necesidad de almacenamiento persistente.
StatefulSet:
Aplicaciones web con estado
Bases de datos como MySQL, PostgreSQL.
Sistemas de mensajería como Kafka, RabbitMQ.
Sistemas de almacenamiento distribuidos como Ceph, GlusterFS.
Aplicaciones que requieren un orden de inicio y apagado específico.
Cómo escribir y aplicar archivos YAML para despliegues (Deployments, Statefulset)
Tal y como se ha comentado en el apartado "Creación de recursos en OpenShift", los Despliegues se define mediante un fichero YAML.
Gestión de Despliegues por interfaz gráfica
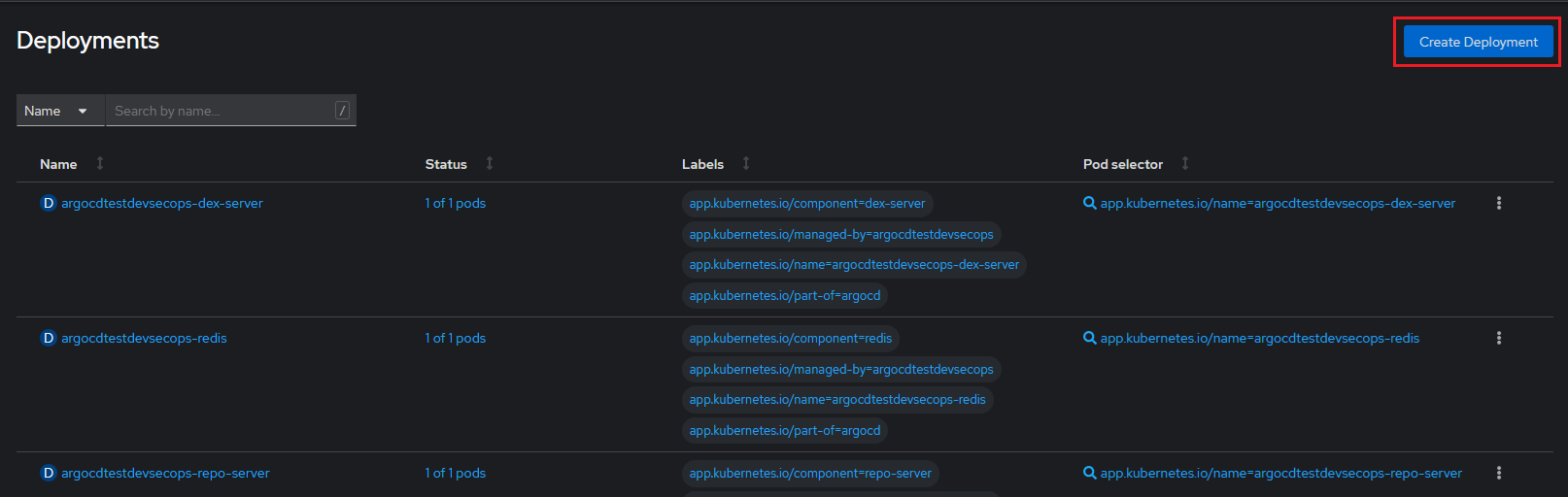
Hay que iniciar sesión en OpenShift y desplegar el menú Workloads, a la izquierda de la pantalla (ver apartado "Descripción de la interfaz gráfica"). Habrá que seleccionar Deployments o StatefulSets según el tipo de despliegue que se vaya a realizar, y se cargará el menú con todos los Deployments o StatefulSets desplegados en OpenShift.

Creación: En Ambos casos el botón para crear el nuevo despliegue esta arriba a la derecha (Create Desployment/StatefulSet). Si se pulsa llevará a la página de creación del objeto de despliegue.
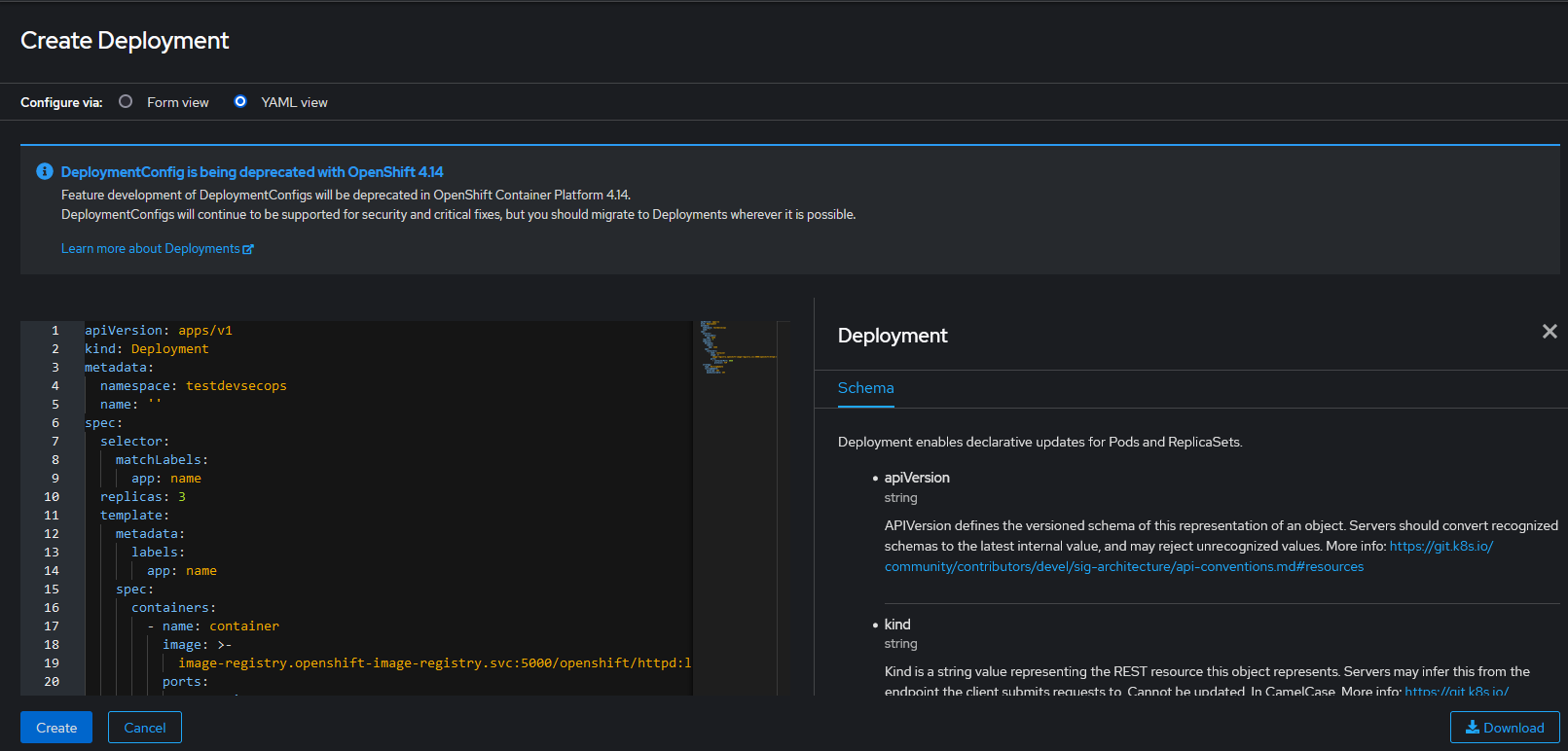
En la siguiente pantalla podremos editar el despliegue predefinido, pegar el contenido de otro o crear uno mediante la vista de formulario. Una vez creado, pulsar el botón "Create" y se creará el objeto de despliegue correspondiente, si está bien definido. A la derecha de la página tendremos una ayuda para definir el esquema.
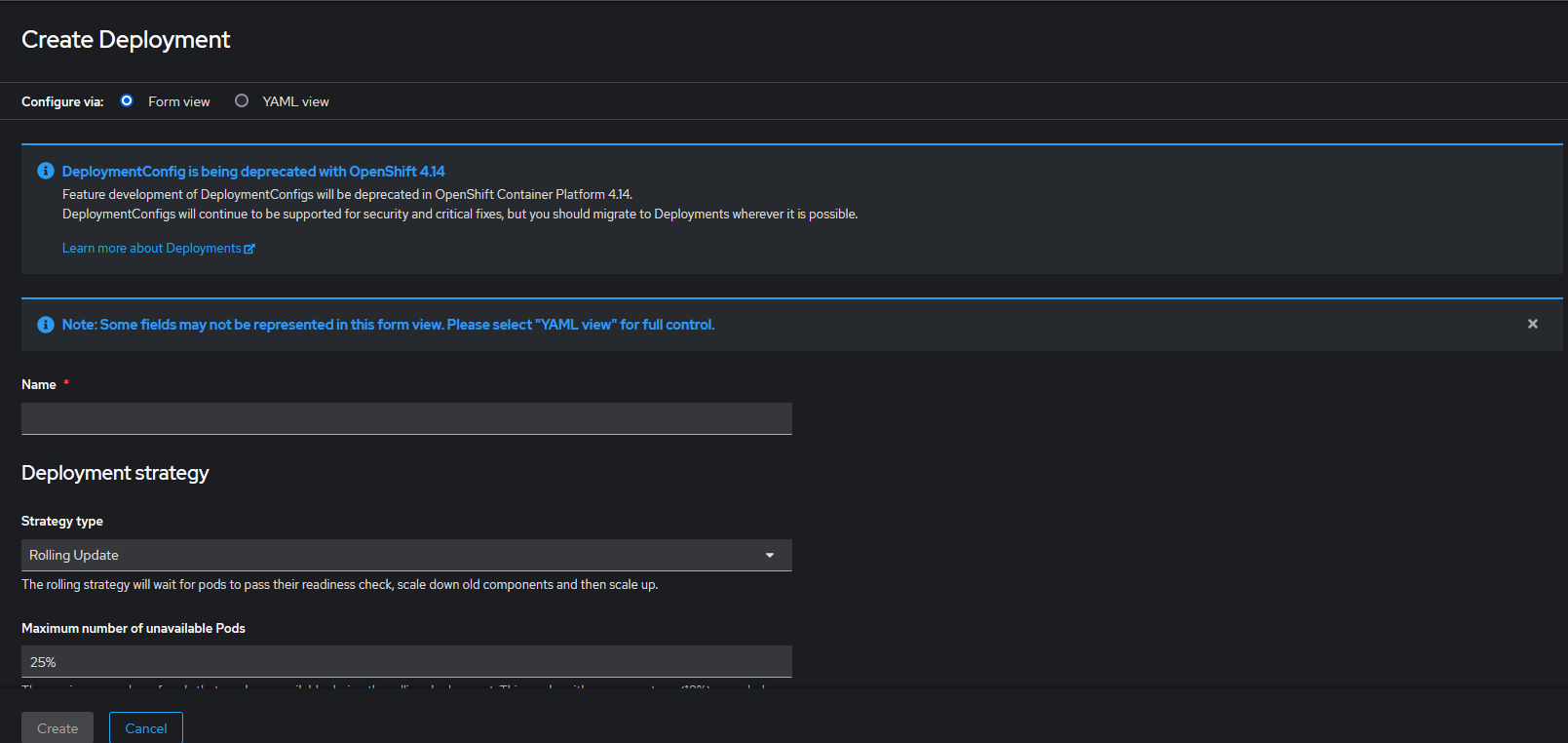
Verificación: Para comprobar que el Despliegue esté creado ir a la página principal de los Desployment o StatefulSet y buscarlo por el nombre especificado en la etiqueta name. Una vez localizado el despliegue verificar, a través de la etiqueta "Status", que se han levantado los Pods correctamente.

Actualización: Para actualizar un PVC, ir a la página del Desployment o StatefulSet correspondiente y pulsar en la pestaña YAML. De esta forma accedemos al editor online, modificamos el YAML y pulsamos el botón "Save".
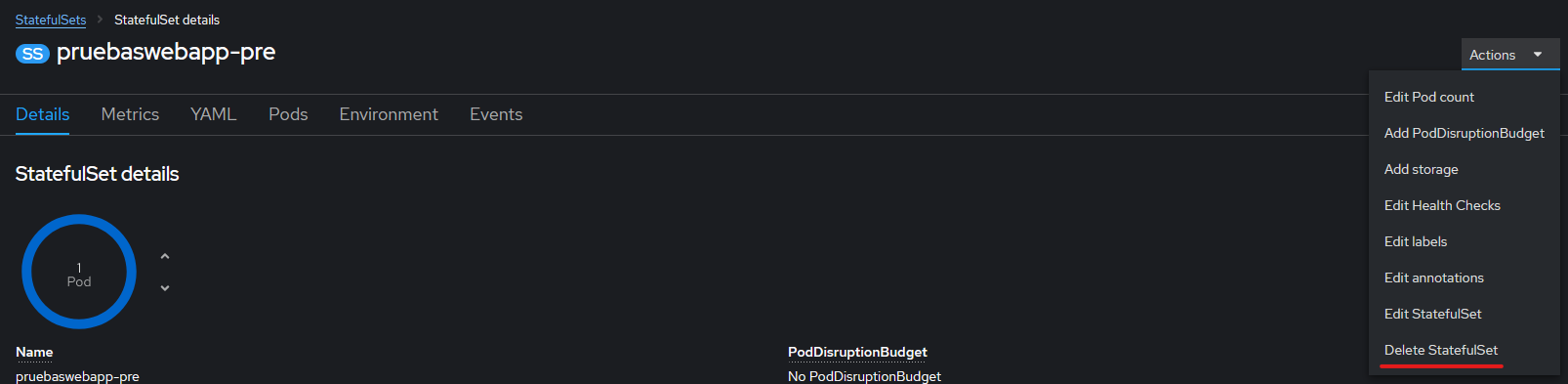
Eliminación: Para eliminar un Desployment o StatefulSet ir al desplegable de arriba a la derecha en la página principal de los Despliegues, y pulsar la opción "Delete Desployment/StatefulSet".
Gestión de Despliegues por línea de comandos
Creación: Aplicar el archivo YAML utilizando el comando:
oc apply -f pruebaswebapp-statefulset.yaml -n testdevsecops
oc apply -f pruebaswebapp-deployment.yaml -n testdevsecopsVerificación: Verificar que el recurso esté creado y funcionando correctamente usando:
oc get statefulset
oc get deploymentActualización: Para actualizar el recurso, modificar el archivo YAML y aplicar los cambios nuevamente con:
oc apply -f pruebaswebapp-statefulset .yaml
oc apply -f pruebaswebapp-deployment.yamlEliminación: Eliminar el recurso con:
oc delete statefulset pruebaswebapp-pre
oc delete deployment pruebaswebapp-pre7Descripción de los principales puntos del fichero de despliegue
En este punto se va a describir algunos de las partes del fichero de despliegue YAML para un objeto de tipo Statefulset. Se va a utilizar como base del ejemplo una modificación del despliegue de la aplicación de prueba pruebaswebapp, para incluir la explicación de funcionalidades aún no implementadas.
IMPORTANTE: En el caso que se necesite crear un objeto Deployment, solo hay que indicarlo en la etiqueta"kind" (kind: Deployment), la configuración de las demás etiquetas es la misma que para el ejemplo con un StatefulSet.
Ejemplo:
apiVersion: apps/v1 #Indica la versión de la API de Kubernetes que se está utilizando para definir el recurso. apps/v1 es la versión estable para StatefulSets.
kind: StatefulSet #Especifica el tipo de recurso que se está definiendo, puede ser StatefulSet o Deployment según el tipo de aplicación a desplegar.
metadata: #Metadatos del recurso.
labels: #Mapa de valores que se pueden usar para organizar y categorizar los objetos.
app: pre-<nombre_componente> #Etiqueta para identificar el StatefulSet, en los pods, Sevice, routes, etc.
name: pre-<nombre_componente>-deploy #El nombre del StatefulSet. Debe ser único en el namespace. IMPORTANTE Sustituir <nombre_componente> por el nombre real del componente.
spec: #Define las identidades de los Pods.
podManagementPolicy: Parallel #Política de gestión de Pods, en este caso, los Pods se crean y eliminan en paralelo
replicas: 1 #Número inicial de réplicas del StatefulSet.
selector: #Define los criterios que K8s debe utilizar para identificar que Pods son gestionados por ese Deployment (esto se realiza con el uso de etiquetas)
matchLabels: #Especifica el conjunto de etiquetas. Los Pods que tienen etiquetas que coinciden con estas especificaciones son seleccionados y gestionados por el deployment.
app: pre-<nombre_componente> # App es la clave de la etiqueta y pre-<nombre_componente> su valor. Es decir, los Pods que tengan la etiqueta app=pre-<nombre_componente>
serviceName: pre-<nombre_componente>-svc #Nombre del servicio asociado al StatefulSet
template:
metadata:
labels:
app: pre-<nombre_componente> #Etiqueta para identificar los Pods.
spec:
containers: #Definición de los contenedores en los Pods.
- envFrom:
- configMapRef:
name: pre-<nombre_componente>-configmap #Referencia al ConfigMap pre-<nombre_componente>-configmap.
- secretRef:
name: pre-<nombre_componente>-secret #Referencia al Secret pre-<nombre_componente>-secret.
image: quay.apps.paas-ges-cica.junta-andalucia.es/testdevsecops/pruebaswebapp:tag #Imagen del contenedor.
imagePullPolicy: Always #Especifica cuando se debe realizar pull de la imagen.
livenessProbe: #Configuración de la sonda de vida para verificar que el contenedor está vivo.
httpGet: #Indica que se va a realizar una solicitud HTTP Get para verificar la vida del contenedor
path: /heatlh #La ruta del endpoint que se va a verificar. IMPORTANTE: Esta ruta debe existir en el componente, ya que probará si está levantado con una petición sobre ella.
port: 8080 #Puerto en el que se realiza la solicitud
initialDelaySeconds: 100 #Tiempo de espera antes de realiza la primera comprobación, después de que el contenedor haya iniciado. IMPORTANTE: verificar la duración de inicio del componente, y si es superior a la indicada aumentarla con amplio margen.
periodSeconds: 5 #Intervalo entre cada comprobación
timeoutSeconds: 20 #Tiempo máximo de espera para la respuesta
readinessProbe: #Configuración de la sonda de preparación para verificar que el contenedor está listo para recibir tráfico.
failureThreshold: 3 #Número de fallos consecutivos que se permiten antes de considerar que la sonda ha fallado.
initialDelaySeconds: 90 #Tiempo de espera antes de realizar la primera comprobación, después de que el contenedor haya iniciado. IMPORTANTE: Esta ruta debe existir en el componente, ya que probará si está levantado con una peti-ción sobre ella.
periodSeconds: 10 #Intervalo entre cada comprobación
successThreshold: 1 #Número de éxitos consecutivos que se requieren para considerar que la sonda ha pasado.
tcpSocket: #Otro tipo de verificación. En este caso, se realiza una comprobación TCP para verificar la preparación del contenedor.
port: 8080 #Puerto en el que se realiza la comprobación.
timeoutSeconds: 1 #Tiempo máximo de espera para la comprobación.
startupProbe: #Configuración de la sonda de inicio para determinar si un contenedor ha iniciado correctamente
httpGet: #Indica que se va a realizar una solicitud HTTP Get para verificar el inicio del contenedor
path: /health #La ruta del endpoint que se va a verificar. IMPORTANTE: Esta ruta debe existir en el componente, ya que probará si está levantado con una peti-ción sobre ella.
port: 8080 #Puerto en el que se realiza la solicitud
initialDelaySeconds: 30 #Tiempo de espera antes de realizar la primera comprobación, después de que el contenedor haya iniciado.
periodSeconds: 10 #Intervalo entre cada comprobación
timeoutSeconds: 5 #Tiempo máximo de espera para la comprobación.
failureThreshold: 30 #Número de fallos consecutivos que se permiten antes de considerar que la sonda ha fallado.
name: pre-<nombre_componente> #Nombre del contenedor.
ports:
- containerPort: 8080 #Puerto a exponer en la IP del Pod.
protocol: TCP #Protocolo del puerto.
resources: #Configuración de los recursos asignados al contenedor.
limits: #Especifica los límites máximos de recursos que el contenedor puede usar. Estos límites son estrictos y no se pueden exceder.
cpu: 500m #El límite máximo de CPU para el contenedor es 500 millicores (0.5 CPUs). Esto significa que el contenedor no puede usar más de medio núcleo de CPU.
memory: 1Gi #El límite máximo de memoria para el contenedor es 1 gibibyte. Esto significa que el contenedor no puede usar más de 1Gi de memoria.
requests: #Especifica los recursos mínimos garantizados para el contenedor. El Scheduler de Kubernetes usa estos valores para decidir en qué nodo colocar el contenedor.
cpu: 200m #El contenedor solicita 200 millicores (0.2 CPUs) como mínimo. Esto es lo que se garantiza que el contenedor obtendrá.
memory: 300Mi #El contenedor solicita 300 mebibytes (aproximadamente 314.6 megabytes) de memoria como mínimo. Esto es lo que se garantiza que el contenedor obtendrá.
terminationMessagePath: /dev/termination-log #Especifica la ruta dentro del contenedor donde se escribe el mensaje de terminación. Estos mensajes pueden incluir información sobre por qué un contenedor fue terminado (como un mensaje de error o el último log antes de terminar).
terminationMessagePolicy: #File Define cómo se recogen los mensajes de terminación del contenedor.
volumeMounts: # Volúmenes que se montarán en el contenedor
- mountPath: /var/opt/config/app.properties # Path en el cual el volumen debería estar montado dentro del contenedor
name: pvc-app-config # Debe coincidir con el nombre del volumen
subPath: app.properties # Path dentro del volumen en el cual el volumen del contenedor debería estar montado
- mountPath: /var/opt/config/ui.properties # Path en el cual el volumen debería estar montado dentro del contenedor
name: pvc-ui-config # Debe coincidir con el nombre del volumen
subPath: ui.properties # Path dentro del volumen en el cual el volumen del contenedor debería estar montado
- name: storage #Debe coincidir con el nombre del volumen
mountPath: /usr/share/nginx/html #Path en el cual el volumen debería estar montado dentro del contenedor
dnsPolicy: ClusterFirst #Establece la política DNS del Pod
imagePullSecrets: #Especifica una lista de secretos que Kubernetes utiliza para autenticar ante los registros de imágenes privadas al descargar las imágenes de contenedor.
- name: quay-secret-token
restartPolicy: Always #Define la política de reinicio del contenedor dentro del Pod.
schedulerName: default-scheduler #Especifica el nombre del planificador que debe utilizarse para este Pod. default-scheduler: Utiliza el planificador predeterminado de Kubernetes para asignar el Pod a un nodo adecuado.
securityContext: {} #Define los parámetros de seguridad para el Pod o los contenedores dentro del Pod.
serviceAccount: pipeline #Especifica la cuenta de servicio a utilizar para el Pod. Las cuentas de servicio son usadas para otorgar permisos específicos a los Pods, permitiéndoles interactuar con el API de Kubernetes y otros recursos del cluster.
volumes: #Lista de Volúmenes que pueden ser montados en el Pod.
- configMap: #Representa un ConfigMap que será inyectado con este volumen.
items: #Lista de claves y rutas a inyectar en el ConfigMap.
- key: app.properties #Identificador para la inyección de datos.
path: app.properties #Ruta relativa al fichero a inyectar en la "key".
name: pre-<nombre_componente>-configmap #Nombre del ConfigMap existente en el clúster
name: pvc-app-config #Nombre del volumen, debe ser único dentro del Pod
- configMap: #Representa un ConfigMap que será inyectado con este volumen.
items: #Lista de claves y rutas a inyectar en el ConfigMap.
- key: ui.properties #Identificador para la inyección de datos.
path: ui.properties #Ruta relativa al fichero a mapear en la "key".
name: pre-<nombre_componente>-configmap #Nombre del ConfigMap existente en el clúster
name: pvc-ui-config #Nombre del volumen, debe ser único dentro del Pod.
- name: storage # Nombre del volumen, debe ser único dentro del Pod
persistentVolumeClaim: # Referencia al PVC en el namespace
claimName: example-pvc #Nombre del PVC
updateStrategy: #Especifica cómo se deben actualizar los Pods de un Deployment o un ReplicaSet cuando se despliega una nueva versión del mismo.
type: RollingUpdate #Estrategia de actualización de los Pods, realizando actualizaciones graduales (rolling updates).Montaje de volúmenes
Los volúmenes se montan en dos partes en el fichero de despliegue, a partir de spec, con las etiquetas 'volume' y 'volumeMounts'. Deben de haberse creado previamente para poder utilizarlos (ver apartado "Almacenamiento Persistente (PVC): Cómo definir los manifiestos de los PVCs").
Ejemplo:
spec: #Define las identidades de los Pods.
...
template:
...
spec:
containers: #Definición de los contenedores en los Pods.
...
volumeMounts: # Volúmenes que se montarán en el contenedor
- name: storage # Debe coincidir con el nombre del volumen
mountPath: /usr/share/nginx/html # Path en el cual el volumen debería estar montado dentro del contenedor
volumes:
- name: storage # Nombre del volumen, debe ser único dentro del Pod
persistentVolumeClaim: # Referencia al PVC en el namespace
claimName: example-pvc # Nombre del PVCMontaje de ConfigMaps y Secrets
Los ConfigMaps y Secrets se montan a partir de la etiqueta spec. Se definen con las claves "configMapRef" y "secretRef", indicando en 'name' cuál es su referencia al ConfigMap y al Secret correspondiente. Estos deben haberse creado previamente en la plataforma (Ver apartado "Configuración de ConfigMaps y Secrets").
Ejemplo:
spec: #Define las identidades de los Pods.
...
template:
...
spec:
containers: #Definición de los contenedores en los Pods.
- envFrom:
- configMapRef:
name: pre-<nombre_componente>-configmap #Referencia al ConfigMap pre-<nombre_componente>-configmap.
- secretRef:
name: pre-<nombre_componente>-secret #Referencia al Secret pre-<nombre_componente>-secret.Se puede inyectar un volumen creado en el clúster, que contenga un fichero de configuración, en un ConfigMap, para ello, hay que el volumen y su punto de montaje en el YAML de despliegue (ver aparatado "Montaje de volúmenes").
Ejemplo, se utilizará como ficheros a inyectar "app.properties" y "ui.properties" creados en el apartado "Creación de un ConfigMap por línea comando a través de un fichero de configuración":
...
spec:
...
template:
...
spec:
containers:
...
volumeMounts: # Volúmenes que se montarán en el contenedor
- mountPath: /var/testdevsecops/config/app.properties # Path en el cual el volumen debería estar montado dentro del contenedor
name: pvc-app-config # Debe coincidir con el nombre del volumen
subPath: app.properties # Path dentro del volumen en el cual el volumen del contenedor debería estar montado
- mountPath: /var/testdevsecops/config/ui.properties # Path en el cual el volumen debería estar montado dentro del contenedor
name: pvc-ui-config # Debe coincidir con el nombre del volumen
subPath: ui.properties # Path dentro del volumen en el cual el volumen del contenedor debería estar montado
...
volumes: #Lista de Volúmenes que pueden ser montados en el Pod.
- configMap: #Representa un ConfigMap que será inyectado con este volumen.
items: #Lista de claves y rutas a inyectar en el ConfigMap.
- key: app.properties #Identificador para la inyección de datos.
path: app.properties #Ruta relativa al fichero a inyectar en la "key".
name: pre-<nombre_componente>-configmap #Nombre del ConfigMap existente en el clúster
name: pvc-app-config #Nombre del volumen, debe ser único dentro del Pod
- configMap: #Representa un ConfigMap que será inyectado con este volumen.
items: #Lista de claves y rutas a inyectar en el ConfigMap.
- key: ui.properties #Identificador para la inyección de datos.
path: ui.properties #Ruta relativa al fichero a mapear en la "key".
name: pre-<nombre_componente>-configmap #Nombre del ConfigMap existente en el clúster
name: pvc-ui-config #Nombre del volumen, debe ser único dentro del PodImagen a utilizar
La imagen que se debe montar en el clúster cuelga de la etiqueta spec. Se utiliza la clave "image" para referenciar la URL que apunta al registro del repositorio en la que se encuentra dicha imagen.
Ejemplo:
spec: #Define las identidades de los Pods.
...
template:
...
spec:
containers: #Definición de los contenedores en los Pods.
...
image: quay.apps.paas-ges-cica.junta-andalucia.es/testdevsecops/pruebaswebapp:tag #Imagen del contenedor.
imagePullPolicy: Always #Especifica cuando se debe realizar pull de la imagen.La etiqueta imagePullPolicy puede tomar tres valores posibles:
Always: Cada vez que se lance el contenedor, se consulta el repositorio de imágenes para obtener la imagen. Si esta está almacenada en la cache local, se utiliza esa, en caso contrario, intenta obtener la del repositorio. El contenedor fallará si la obtención de la imagen falla.
IfNotPresent: Se obtiene la imagen del repositorio de imágenes solo si no está presente localmente. El contenedor fallará si la imagen no está presente y la obtención de la imagen falla.
Never: No intenta recuperar la imagen del repositorio. Si la imagen existe localmente inicia el contendedor, en caso contrario el inicio falla.
Para más información visitar el siguiente enlace:
https://kubernetes.io/docs/concepts/containers/images/#updating-images
Límites de Recursos: Cómo establecer límites de recursos para Pods
Dentro del YAML hay que limitar los recursos que utilizarán los Pods, esto se logra con la etiqueta "resources", que cuelga de spec, y en ella se indicará los límites máximos (limits) y mínimos (requests) de recursos que se permitirá utilizar al contenedor. Dentro de cada límite habrá que especificar la cantidad de cpu y memoria.
Ejemplo:
spec: #Define las identidades de los Pods.
...
template:
...
spec:
containers: #Definición de los contenedores en los Pods.
...
resources: #Configuración de los recursos asignados al contenedor.
limits: #Especifica los límites máximos de recursos que el contenedor puede usar. Estos límites son estrictos y no se pueden exceder.
cpu: 500m #El límite máximo de CPU para el contenedor es 500 millicores (0.5 CPUs). Esto significa que el contenedor no puede usar más de medio núcleo de CPU.
memory: 1Gi #El límite máximo de memoria para el contenedor es 1 gibibyte. Esto significa que el contenedor no puede usar más de 1Gi de memoria.
requests: #Especifica los recursos mínimos garantizados para el contenedor. El Scheduler de Kubernetes usa estos valores para decidir en qué nodo colocar el contenedor.
cpu: 200m #El contenedor solicita 200 millicores (0.2 CPUs) como mínimo. Esto es lo que se garantiza que el contenedor obtendrá.
memory: 300Mi #El contenedor solicita 300 mebibytes (aproximadamente 314.6 megabytes) de memoria como mínimo. Esto es lo que se garantiza que el contenedor obtendrá.El valor de los recursos para "cpu" se mide en unidades de cpu y viene indicado en millicpu o millicore, se puede escribir tanto como 500m como 0.5. Para los recursos "memory" se miden por bytes, pudiendo utilizarse sufijos como E, P, T, G, M, k. También permitir utilizar su equivalente en potencia de dos bytes Ei, Pi, Ti, Gi, Mi, Ki, por lo que 129M (Megabytes) correspondería con 123Mi (Mebibytes).
Para más información visitar el siguiente enlace:
https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
Sondas de salubridad
Kubernetes permite realizar diagnósticos periódicos sobre los contenedores, esto se conoce como probes o sondas. Se pueden configurar en el YAML y hay 3 tipos:
livenessProbe: Indica si el contendedor está ejecutándose. Si el sondeo falla, kubelet matará al contenedor y esté quedará sujeto a su política de reinicio.
ReadinessProbe: Indica si el contenedor está listo para recibir peticiones. Si el sondeo falla se eliminará la IP del Pod. Antes de su inicio su estado es de Fallo.
StartupProbe: Indica si la aplicación dentro de contenedor se ha iniciado. El resto de sondeos se á hasta que este se realice correctamente. Si el sondeo falla, kubelet matará al contenedor y esté quedará sujeto a su política de reinicio. Es especialmente útil en aplicaciones que tardan mucho en iniciar.
Si no se define una sonda, su estado por defecto será de Éxito.
Para más información visitar el siguiente enlace:
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#container-probes
Para definir las sondas en el fichero de despliegue hay que indicar la etiqueta correspondiente a la sonda que se quiera incluir.
Ejemplo:
spec: #Define las identidades de los Pods.
...
template:
...
spec:
containers: #Definición de los contenedores en los Pods.
...
livenessProbe: #Configuración de la sonda de vida para verificar que el contenedor está vivo.
httpGet: #Indica que se va a realizar una solicitud HTTP Get para verificar la vida del contenedor
path: /heatlh #La ruta del endpoint que se va a verificar. IMPORTANTE: Esta ruta debe existir en el componente, ya que probará si está levantado con una petición sobre ella.
port: 8080 #Puerto en el que se realiza la solicitud
initialDelaySeconds: 100 #Tiempo de espera antes de realiza la primera comprobación, después de que el contenedor haya iniciado. IMPORTANTE: verificar la duración de inicio del componente, y si es superior a la indicada aumentarla con amplio margen.
periodSeconds: 5 #Intervalo entre cada comprobación
timeoutSeconds: 20 #Tiempo máximo de espera para la respuesta
readinessProbe: #Configuración de la sonda de preparación para verificar que el contenedor está listo para recibir tráfico.
failureThreshold: 3 #Número de fallos consecutivos que se permiten antes de considerar que la sonda ha fallado.
initialDelaySeconds: 90 #Tiempo de espera antes de realizar la primera comprobación, después de que el contenedor haya iniciado. IMPORTANTE: Esta ruta debe existir en el componente, ya que probará si está levantado con una petición sobre ella.
periodSeconds: 10 #Intervalo entre cada comprobación
successThreshold: 1 #Número de éxitos consecutivos que se requieren para considerar que la son-da ha pasado.
tcpSocket: #Otro tipo de verificación. En este caso, se realiza una comprobación TCP para verificar la preparación del contenedor.
port: 8080 #Puerto en el que se realiza la comprobación.
timeoutSeconds: 5 #Tiempo máximo de espera para la comprobación.
startupProbe: #Configuración de la sonda de inicio para determinar si un contenedor ha iniciado correctamente
httpGet: #Indica que se va a realizar una solicitud HTTP Get para verificar el inicio del contenedor
path: /health #La ruta del endpoint que se va a verificar. IMPORTANTE: Esta ruta debe existir en el componente, ya que probará si está levantado con una petición sobre ella.
port: 8080 #Puerto en el que se realiza la solicitud
initialDelaySeconds: 30 #Tiempo de espera antes de realizar la primera comprobación, después de que el contenedor haya iniciado. IMPORTANTE: Esta ruta debe existir en el componente, ya que probará si está levantado con una petición sobre ella.
periodSeconds: 10 #Intervalo entre cada comprobación
timeoutSeconds: 5 #Tiempo máximo de espera para la comprobación.
failureThreshold: 30 #Número de fallos consecutivos que se permiten antes de considerar que la sonda ha fallado.
Otros puntos de montaje
TerminationMessagePolicy:
spec: #Define las identidades de los Pods.
...
template:
...
spec:
containers: #Definición de los contenedores en los Pods.
...
terminationMessagePolicy: #File Define cómo se recogen los mensajes de terminación del contenedor.Define cómo se recogen los mensajes de terminación del contenedor. En este caso, File, indica que se debe tomar el contenido del archivo especificado por terminationMessagePath para obtener el mensaje de terminación. Como alternativa, se puede utilizar "FallbackToLogsOnError", que indica que si el archivo especificado en terminationMessagePath está vacío y el contenedor termina con un estado de error, Kubernetes debería usar el último bloque de logs del contenedor como mensaje de terminación.
dnsPolicy: Establece que política DNS utilizará el Pod
spec: #Define las identidades de los Pods.
...
template:
...
spec:
...
dnsPolicy: ClusterFirst #Establece la política DNS del PodPuede tomar los siguientes valores posibles:
ClusterFirst: Indica que el pod debe usar primero el DNS del clúster a menos que hostNetwork sea true. Si el DNS del clúster no puede resolver el nombre, utiliza la configuración DNS predeterminada del nodo. (según lo determinado por kubelet). Este es el valor por defecto para los Pods que se ejecutan dentro del clúster.
ClusterFirstWithHostNet: Indica que el pod debe usar primero el DNS del clúster, Si el DNS del clúster no puede resolver el nombre, utiliza la configuración DNS predeterminada del nodo (según lo determinado por kubelet).
Default: Indica que el pod debe utilizar la configuración DNS predeterminada del nodo (según lo determinado por kubelet).
None: Desactiva completamente la resolución de DNS para el Pod. Los parámetros de DNS, como servidores de nombres y rutas de búsqueda, se deben definir mediante DNSConfig.
restartPolicy:
spec: #Define las identidades de los Pods.
...
template:
...
spec:
...
restartPolicy: Always #Define la política de reinicio del contenedor dentro del Pod.Define la política de reinicio del contenedor dentro del Pod.
Always: Reinicia automáticamente el contenedor después de cualquier terminación. Este es el valor por defecto para los Pods administrados por un Deployment, ReplicaSet o StatefulSet.
OnFailure: Solo reinicia el contenedor si termina con error (estado de la salida distinta de cero).
Never: No reinicia nunca automáticamente el contenedor terminado.
SecurityContext:
spec: #Define las identidades de los Pods.
...
template:
...
spec:
...
securityContext: {} #Define los parámetros de seguridad para el Pod o los contenedores dentro del Pod.Define los parámetros de seguridad para el Pod o los contenedores dentro del Pod. En el ejemplo está vacío, lo que significa que no se ha aplicado ninguna configuración de seguridad adicional, pero se pueden incluir opciones como:
runAsUser: El ID de usuario con el que debe ejecutarse el contenedor.
runAsGroup: El ID de grupo con el que debe ejecutarse el contenedor.
fsGroup: El ID de grupo que debe poseer los archivos creados por el contenedor.
readOnlyRootFilesystem: Si el sistema de archivos raíz del contenedor debe ser de solo lectura.
updateStrategy:
spec: #Define las identidades de los Pods.
...
updateStrategy: #Especifica cómo se deben actualizar los Pods de un Deployment o un ReplicaSet cuando se despliega una nueva versión del mismo.
type: RollingUpdate #Estrategia de actualización de los Pods, realizando actualizaciones graduales (rolling updates).Especifica cómo se deben actualizar los Pods de un Deployment o un ReplicaSet cuando se despliega una nueva versión del mismo.
type: Estrategia de actualización de los Pods, puede tomar los valores:
RollingUpdate: Actualiza gradualmente los Pods antiguos por los nuevos. Durante el proceso de actualización, Kubernetes mantiene un número especificado de réplicas del conjunto de Pods antiguos y del nuevo conjunto de Pods. Se inicia el despliegue de los nuevos Pods mientras se retienen los Pods antiguos para mantener la disponibilidad y la capacidad de respuesta de la aplicación.
Recreate: Detiene todos los Pods antiguos antes de iniciar los nuevos Pods. Durante este proceso, puede haber una breve interrupción en el servicio, ya que todos los Pods antiguos se eliminan antes de que se creen los nuevos Pods. Esto puede ser adecuado para actualizaciones que requieren una parada de servicio.
Auditoria y Registro
Logs: Acceso y gestión de logs de aplicaciones y del sistema
OpenShift permite monitorizar las aplicaciones desplegadas en el clúster, ver los logs de las instancias o reiniciar los Pods si fuera necesario. Todo esto se puede lograr mediante interfaz gráfica o línea de comandos.
Logs de Aplicaciones
Para poder visualizar los logs de una aplicación hay que dirigirse a la página de los StatefulSet o Deployment y buscar el despliegue que queramos revisar.
Cuando se elija uno de los despliegues, aparecerá la siguiente pantalla indicando el número de Pods y cuantas ejecuciones de ellos hay. Para ver los logs de cada Pod hay que ir a la pestaña Pods y si aparecen más de una instancia, seleccionar una de ellas. Seleccionar el Pod a consultar. Se verá toda la información que se redirija a salida estándar.
En el siguiente enlace se pueden encontrar algunas normas a tener en cuenta para el diseño de los logs de información:
En la nueva pantalla seleccionar la pestaña Logs para acceder a ellos
Aparecerán el log del Pod, el cual podemos descargarlo como fichero, abrirlo en pantalla completa o en una ventana nueva con el texto plano.
OpenShift Container Platform CLI
La CLI de OpenShift permite exponer comandos para administrar las aplicaciones e interactuar con cada recurso de la plataforma.
Para poder utilizar los comandos primero hay que conectarse con OpenShift mediante una autenticación con Token. Este proceso esta detallado en el apartado "Obtención del Token para la línea de comandos".
Comandos útiles
Tanto OpenShift como Kubernetes disponen de una herramienta para la línea de comandos, oc y kubectl respectivamente. Con ambas se pueden listar recursos, aplicar y eliminar configuraciones, ver registros, etc.
Comandos de OpenShift
Listar Recursos
Obtener todos los Pods en el namespace actual:
oc get podsObtener todos los servicios en un namespace específico:
oc get svc -n <namespace>Obtener todos los routes:
oc get routesDescribir Recursos
Describir un Pod específico:
oc describe pod <pod-name>Describir un servicio:
oc describe svc <service-name>Describir un route:
oc describe route <route-name>Ver Registros
Ver los logs de un Pod:
oc logs <pod-name>Ver los logs de un contenedor específico en un Pod:
oc logs <pod-name> -c <container-name>Aplicar y Eliminar Configuraciones
Aplicar un archivo de configuración:
oc apply -f <file.yaml>Eliminar un recurso definido en un archivo de configuración:
oc delete -f <file.yaml>Escalado de Aplicaciones
Escalar un deployment a un número específico de réplicas:
oc scale deployment <deployment-name> --replicas=<number>Ejecución de Comandos en un Pod
Ejecutar un comando en un Pod:
oc exec -it <pod-name> -- <command>Obtener una shell dentro de un Pod:
oc exec -it <pod-name> -- /bin/Configuración de Contextos y Namespaces
Cambiar el proyecto actual:
oc project <project-name>Validación de yaml en local
Validación en el servidor: que hace una simulación de despliegue pero sin llegar a desplegar para comprobar si es correcto el formato y las etiquetas.
oc apply -f archivo.yaml --dry-run=serverValidación en local: los valida mediante el cli de Openshift
oc apply -f archivo.yaml --dry-run=client
Comandos de kubectl
Listar Recursos
Obtener todos los Pods en el namespace actual:
kubectl get podsObtener todos los servicios en un namespace específico:
kubectl get svc -n <namespace>Obtener todos los deployments:
kubectl get deploymentsObtener todos los secrets:
kubectl get secretsDescribir Recursos
Describir un Pod específico:
kubectl describe pod <pod-name>Describir un servicio:
kubectl describe svc <service-name>Describir un deployment:
kubectl describe deployment <deployment-name>Ver Registros
Ver los logs de un Pod:
kubectl logs <pod-name>Ver los logs de un contenedor específico en un Pod:
kubectl logs <pod-name> -c <container-name>Aplicar y Eliminar Configuraciones
Aplicar un archivo de configuración:
kubectl apply -f <file.yaml>Eliminar un recurso definido en un archivo de configuración:
kubectl delete -f <file.yaml>Escalado de Aplicaciones
Escalar un deployment a un número específico de réplicas:
kubectl scale deployment <deployment-name> --replicas=<number>Ejecución de Comandos en un Pod
Ejecutar un comando en un Pod:
kubectl exec -it <pod-name> -- <command>Obtener una shell dentro de un Pod:
kubectl exec -it <pod-name> -- /bin/Configuración de Contextos y Namespaces
Cambiar el contexto actual:
kubectl config use-context <context-name>Cambiar el namespace por defecto:
kubectl config set-context --current --namespace=<namespace>Crear aplicaciones con 'oc new-app'
El comando oc new-app en OpenShift es una herramienta para crear aplicaciones a partir de código fuente, imágenes de contenedor existentes, o plantillas. Facilita el despliegue rápido de aplicaciones en el clúster.
Crear Aplicaciones a partir de Código Fuente: Puedes crear una aplicación directamente desde un repositorio de código fuente. OpenShift analizará el código, seleccionará la estrategia de construcción adecuada y desplegará la aplicación.
oc new-app https://github.com/usuario/repositorio.git --name nombre-aplicacionCrear Aplicaciones a partir de Imágenes de Contenedor: También puedes desplegar aplicaciones utilizando imágenes de contenedor preexistentes de registries como Docker Hub o registries privados.
oc new-app docker.io/nombreusuario/nombreimagen:tag --name nombre-aplicacionCrear una aplicación desde una imagen en un registry privado
oc new-app registryprivado.com/nombreusuario/nombreimagen:tag --name nombre-aplicacionCrear Aplicaciones a partir de Plantillas: Las plantillas permiten definir una serie de recursos (servicios, rutas, configuraciones, etc.) que se pueden desplegar juntos.
oc new-app -f plantilla.yaml --param NOMBRE_PARAMETRO=valorOtras Opciones Útiles del Comando oc new-app
Especificar Variables de Entorno: Puedes establecer variables de entorno durante la creación de la aplicación.
oc new-app https://github.com/usuario/repositorio.git --name nombre-aplicacion -e NOMBRE_VARIABLE=valorDesplegar desde un Dockerfile: Si tu repositorio de código fuente contiene un Dockerfile, OpenShift puede construir la imagen y desplegarla.
oc new-app https://github.com/usuario/repositorio.git --name nombre-aplicacion --strategy=dockerRecursos Adicionales
Documentación Oficial: Enlaces a la documentación oficial de OpenShift
Documentación oficial de OpenShift:
https://docs.openshift.com/container-platform/4.14/welcome/index.html
Documentación oficial de Kubernetes
https://kubernetes.io/docs/home/
API Conventions de Kubernetes
Tutoriales y documentación
OpenShift and Kubernetes learning
https://developers.redhat.com/learn/openshift
Curso OpenShift 4
https://www.youtube.com/watch?v=y4fSNCXYuXU&list=PLkqaOL-oB94FrX-0stCmyCp89NAY4PFGd&pp=iAQB
OpenShift tutorial español
https://www.youtube.com/watch?v=LTisjNetUzA&list=PLrb1e2Mp6N_uKpOGrjx74yYJV_S3DXhOZ&index=1
- Reliable Autonomic Distributed Object Store ↩
- Controlled Replication Under Scalable Hashing ↩
- Object Storage Devices: Son los servicios de fondo que realmente se encargan de gestionar los archivos: son responsables del almacenamiento, el duplicado y la restauración de los datos. Se recomienda tener al menos tres OSD en el cluster. ↩
- Metadata server: Se encargan de almacenar metadatos como, por ejemplo, rutas de almacenamiento, sellos de tiempo y nombres de los archivos guardados en CephFS, por motivos de rendimiento. Están creados siguiendo el estándar POSIX y pueden solicitarse mediante líneas de comando de Unix, como ls, find y like. ↩