Información general

Objetivos, características y beneficios
API es la abreviatura de Application Programming Interface (Interfaz de Programación de Aplicaciones), pudiendose resumir como una funcionalidad o conjunto de funcionalidades preparadas para ser utilizadas por otro software.
Este software que se comunica con la API puede ser interno, de la propia Junta de Andalucía, o bien externo, de terceros, y el control del acceso de los diferentes programas a la funcionalidad que se proporciona es una parte fundamental de la definición de una API.
Mediante la utilización y publicación de APIs, los desarrolladores de aplicaciones pueden acceder a ciertos activos de datos o funciones definidos expresamente para su consumo a través de una interfaz documentada y sencilla de utilizar.
Por tanto, el objetivo principal de una arquitectura de APIs es ofrecer un mecanismo de exposición y gobierno de APIs bien documentadas y reutilizables, que permitan el acceso a distintas funcionalidades de la Junta de Andalucía mediante protocolos más “entendibles”, de una manera controlada y segura; sin necesidad de conocer cómo se realiza internamente el proceso.
Las arquitecturas de APIs ofrecen muchas características y funcionalidades orientadas a la publicación y gobierno de APIs, de las que se pueden destacar:
- La gestión de APIs o API Management implica la catalogación de la API para su consumo (publishing), exposición (promoting), control, monitorización (overseeing) y ejecución en un entorno seguro, fiable y escalable.
- Esta catalogación puede ser tan amplia como escenarios de exposición se necesiten, dos de ellos son fundamentales:
- Interno: Contiene las APIs que podrán ser consumidas por aplicaciones internas o de confianza.
- Externo: Contiene las APIs que podrán ser consumidas por aplicaciones de otras organizaciones y otros desarrolladores ajenos.
- La arquitectura de APIs, permite la comunicación a través de un conjunto de protocolos estándares basados en HTTP y en el intercambio de objetos JSON, entre los cuales, se autorizan a usar los siguientes:
- REST: REST es el protocolo de API más común, definido por un conjunto de restricciones arquitectónicas y destinado a una amplia adopción por parte de muchos consumidores de API. Es la forma más simple de comunicación entre un servidor y un cliente. Al utilizar el protocolo HTTP, los clientes pueden utilizar diferentes verbos como GET, PUT, POST, PATCH y DELETE para acceder o actualizar contenido en el servidor remoto.
Es importante tener en cuenta que las API REST no tienen estado debido a la naturaleza del protocolo HTTP. Esto significa que cada solicitud del cliente al servidor debe contener toda la información necesaria para comprender y completar la solicitud. Se usará OpenAPI versión 3 o superior para la definición de los contratos. - GraphQL: GraphQL es una sintaxis que describe cómo realizar una solicitud de datos precisa. Se recomienda implementar GraphQL para el modelo de datos de una aplicación con muchas entidades complejas que hacen referencia entre sí.
La característica central de GraphQL es su capacidad para solicitar y recibir sólo los datos específicos solicitados, desde un único endpoint. Esto evita la necesidad de hacer múltiples llamadas para obtener datos de múltiples recursos (underfetching) y también evita la recuperación de más información de la que realmente necesita el cliente (overfetching).
Para ello, se comienza con la creación de un esquema, que es una descripción de todas las consultas que puede realizar una API GraphQL y todos los tipos que devuelven. La creación de esquemas es difícil ya que requiere una escritura estricta en el lenguaje de definición de esquemas (SDL). - gRPC: Una llamada a procedimiento remoto (RPC) es una especificación que permite la ejecución remota de una función en un contexto diferente. RPC amplía la noción de llamada a procedimientos locales pero la sitúa en el contexto de una API HTTP. gRPC es la versión de RPC con soporte conectable para equilibrio de carga, seguimiento, verificación de estado y autenticación, es ideal para conectar microservicios. gRPC es la opción adecuada para enviar comandos a un sistema remoto. Se basa en HTTP/2, protocol buffers y otros stacks tecnológicos modernas para garantizar la máxima seguridad, rendimiento y escalabilidad de API.
Al tener una integración directa entre un único proveedor de datos y un consumidor, no se pierde mucho tiempo transmitiendo metadatos, como lo hace el patrón REST. Al utilizar HTTP/2 internamente, gRPC puede optimizar la capa de red y hacerla muy eficiente al enviar grandes cantidades de mensajes. - WebSocket: WebSocket es un protocolo dúplex utilizado principalmente en el canal de comunicación cliente-servidor. Es de naturaleza bidireccional, lo que significa que la comunicación se produce de un lado a otro entre el cliente y el servidor.
La conexión dura hasta que cualquiera de los participantes la desconecta. Una vez que una parte interrumpe la conexión, la segunda parte no podrá comunicarse, ya que la conexión falla automáticamente en su parte frontal.
WebSocket necesita soporte de HTTP para iniciar la conexión y se usa principalmente cuando se trata de una transmisión fluida de datos y de tráfico asíncrono (aplicaciones en tiempo real, chats, cuadros de mando con datos en vivo, …).
- REST: REST es el protocolo de API más común, definido por un conjunto de restricciones arquitectónicas y destinado a una amplia adopción por parte de muchos consumidores de API. Es la forma más simple de comunicación entre un servidor y un cliente. Al utilizar el protocolo HTTP, los clientes pueden utilizar diferentes verbos como GET, PUT, POST, PATCH y DELETE para acceder o actualizar contenido en el servidor remoto.
- A la hora de diseñar una API, de forma general, se seguirá el enfoque API-First (primero el diseño), que implica la creación una definición API (contrato) detallada antes de escribir cualquier código. Aunque parezca más lento y haya que dedicar más tiempo a pensar cómo se va a diseñar la API, los desarrolladores pueden utilizar estas definiciones (como una especificación OpenAPI) para generar código en múltiples lenguajes de programación y mejorar la consistencia entre las implementaciones en una fracción del tiempo.
- Existe un segundo enfoque, denominado Code-First, que implica escribir el código primero y documentarlo una vez hecho. Podría ser un buen enfoque para la creación rápida de prototipos o proyectos con un desarrollo altamente iterativo.
- Una característica propia de las arquitecturas de APIs y los API Manager, es el concepto de producto. Este concepto nace para facilitar que las aplicaciones que vayan a consumir las APIs sepan cuáles van a necesitar en función del negocio que necesiten.
Un producto API es un mecanismo de empaquetado lógico que se puede utilizar cuando se necesita agrupar un conjunto de recursos de varias API y exponerlo como una interfaz API separada, que los suscriptores pueden consumir. Los productos API ofrecen a los publicadores de APIs la capacidad de “reempaquetar” sus API existentes en varias combinaciones para ofrecer una experiencia personalizada a sus suscriptores.
Los suscriptores verán este producto API como una entidad separada, independiente de las API con las que comparte sus recursos, y funcionará de la misma manera que cualquiera de las API estándar existentes.
Los principales beneficios de la arquitectura de APIs son las siguientes:
- Acceso: Facilita el acceso a datos o funciones mediante una interfaz documentada y sencilla de utilizar.
- Reutilización: Facilita la reutilización de un código probado y funcionando correctamente sin conocer cómo realiza internamente el proceso.
- Independencia: Debido a la separación entre cliente y servidor, los desarrolladores que van a consumir las APIs no necesitan saber cómo o qué tecnologías hay por debajo de ellas para usar el lenguaje o tecnología que mejor se pueda adaptar.
- Monitorización: Permite realizar una monitorización de consumo de las APIs con el fin de comprobar su funcionamiento, su grado de uso y anticiparse a posibles problemas.
- Seguridad: Permite definir detalladamente aspectos de seguridad y control de acceso al interfaz, aislando de este modo los servicios consumidores.
- Versionado: Permite exponer varias versiones de la misma funcionalidad, simplificando el despliegue de nuevas funcionalidades sin impactar en los consumidores existentes.
Principios
Partiendo de los principios generales definidos en la arquitectura global de servicio y que aplican en su totalidad a la arquitectura de APIs, las APIs poseen una serie de principios específicos que se listan a continuación:
- Detectable
- Reutilizable
- Versionado
(*) Puede consultarse el listado de Principios Tecnológicos Generales.
Detectable
Las API deben ser fácilmente detectables. Si los usuarios no pueden encontrar información, ésta no existe para ellos.
Dicha información debe tener referencias a todas las versiones de la API que se admiten y debería mencionar explícitamente los cambios importantes.
La documentación debe proporcionar una descripción general que cubra convenciones básicas, URL base, etc., proporcionar todo lo necesario para que un desarrollador pueda usarla, sepa qué tiene que proporcionar y qué va a recibir enumerando códigos de error con posibles casos de uso.
Reutilizable
Las API deben diseñarse para su reutilización. Los componentes reutilizables reducen los costes de desarrollo y reducen el tiempo de comercialización para la entrega de nuevas funciones de software.
Versionado
Las APIs están en constante evolución y debe garantizarse que seguirán siendo accesibles para cada aplicación que requiera acceder a las mismas mientras estén activas. Para garantizar esto debe diseñarse un sistema de versionado eficiente que permita coexistir distintas versiones de la API, enumerando claramente los cambios importantes.
Componentes
Los principales componentes que forman parte de la arquitectura de referencia de APIs son:
- Gestor de APIs
- Publicador de APIs
- Analítica de APIs
- Gestor del tráfico
- API Portal
- Caché
- Colector de observabilidad
En el siguiente diagrama de arquitectura se muestra la ubicación de dichos componentes dentro de la arquitectura global:
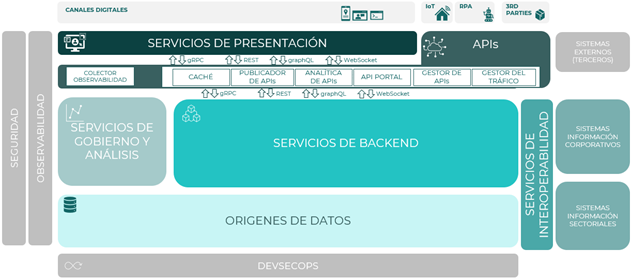
Gestor de APIs
El gestor de apis es la herramienta de administración, desarrollo, gestión, implementación de políticas, monitorización y publicación de las APIs y organizaciones desde el punto de vista del productor o dueño de las APIs.
Incluye las herramientas de definición y desarrollo de las APIs. Permite la separación de su gobierno, el uso de diferentes organizaciones, creación de catálogos y la gestión del ciclo de vida, las políticas de uso, la seguridad y la visibilidad de las APIs.
Publicador de APIs
Es la herramienta que permite a los productores de APIs desarrollar, documentar, probar y versionar las API con facilidad. Además, permite su publicación y la aplicación de algunas políticas de uso.
Analítica de APIs
Herramienta de supervisión y análisis de las APIs desarrolladas. Permite crear alertas y notificaciones ante eventos concretos.
Gestor del tráfico
El componente de gestor de tráfico, como su propio nombre indica, ayuda a los usuarios a regular el tráfico de APIs, ser capaz de publicar las APIs a distintos niveles de servicio y protegerlas proporcionado políticas de control de throttling.
API Portal
El API Portal es el marketplace donde estarán expuestas las APIs. Sirve como puente entre el productor de la API (el equipo que la crea) y el consumidor de la API (los desarrolladores que se integran con la organización). Cubre todas las necesidades desde el punto de vista del consumidor.
Este portal debe proporcionar documentación sobre la funcionalidad de una API y ejemplos de peticiones de las APIs para que los usuarios puedan comenzar a consumirlas sin encontrar obstáculos. También proporcionan un registro de las API a medida que se actualizan y modifican con nuevas versiones.
Los desarrolladores se pueden registrar en el Portal, suscribirse a APIs y crear aplicaciones para poder consumirlas. Además, mediante comunidades, foros y valoraciones, le permitirá comunicarse con la organización para informar sobre la calidad de la API o sobre cualquier posible error que haya encontrado; así como enviarles comentarios para que puedan mejorar el atractivo y el valor de sus APIs.
Caché
Deberá utilizarse un sistema de caché que permita reducir el número de peticiones a servicios de backend e interoperabilidad, incluso a validaciones de autorizaciones para optimizar las comunicaciones y los tiempos de respuesta.
Colector de observabilidad
La observabilidad es el grado en el que comprendemos el estado interno o la condición de un sistema complejo basándonos solo en el conocimiento de sus salidas externas. Cuanto más observable sea un componente software, más rápida y precisa será su respuesta ante cualquier tipo de problema.
La observabilidad se basa en la generación, recolección y análisis de métricas, trazas y log:
- Métricas: Las métricas permiten gestionar la salud individual de un componente software.
- Trazas: Analizan el estado de una petición y nos permite comprobar si estas peticiones navegan correctamente a través de los diferentes componentes software.
- Logs: Mensajes que dan información variada sobre un componente software.
Patrones de arquitectura y diseño
A continuación, se describirán el conjunto de patrones que permite diseñar una arquitectura de API que cumpla con los principios ya descritos usando para ello los componentes definidos en el apartado anterior.
Patrones para la resiliencia de APIs
Circuit breaker
En un sistema distribuido, cuando un servicio hace una llamada síncrona a otro servicio existe un permanente riesgo de fallo. Como el cliente y el servicio están en procesos separados, un servicio puede no responder a tiempo la solicitud de un cliente porque está caído por fallo o mantenimiento o por existir problemas en la red que ralentizan o hagan imposible la comunicación. Dado que habitualmente el cliente está bloqueado mientras espera la respuesta, cualquier problema en un servicio puede generar un fallo en cascada en todo el sistema.
Este tipo de problemas se puede gestionar mediante la combinación de una serie de mecanismos:
- Indisponibilidad de la red: Estableciendo timeouts que impidan el bloqueo indefinido de un cliente al no obtener respuesta del servicio.
- Limitación de peticiones a un servicio: Limitando el número de peticiones por segundo que puede recibir un servicio para evitar que se sature y deje de funcionar correctamente. Esto implicaría que, aunque el servicio funcione correctamente, se devolverá un error específico indicando que se ha superado el límite establecido. Esta limitación no será común para todos los servicios ya que requerirá de un análisis del mismo junto que distintos tipos de pruebas de carga para realizar las configuraciones más idóneas en cada caso.
Principios que aplican:
- Resiliencia sobre recuperación
Referencia: Pattern: Circuit Breaker
Patrones para el acceso a los servicios backend
API Gateway
Un API Gateway es un servicio que hace de enlace entre un servicio backend y el mundo exterior. Este servicio es el responsable, entre otras cosas, de enrutar las peticiones para que lleguen al destino, gestionar la seguridad y adaptar la petición y la respuesta.
El patrón API Gateway establece una fachada donde, cuando una aplicación necesita acceder a un microservicio, la aplicación manda una petición al API Gateway con la información que necesita enviar/recibir e indicando a qué servicio quiere mandar la petición. El API Gateway tiene mapeados todos los servicios y enruta la petición para que llegue a destino. Cuando la respuesta del servicio llega quien primero la recoge es el API Gateway, el cual, entre otras acciones, se asegura de que la respuesta recibida sea segura antes de enrutarla a la aplicación que la solicitó.
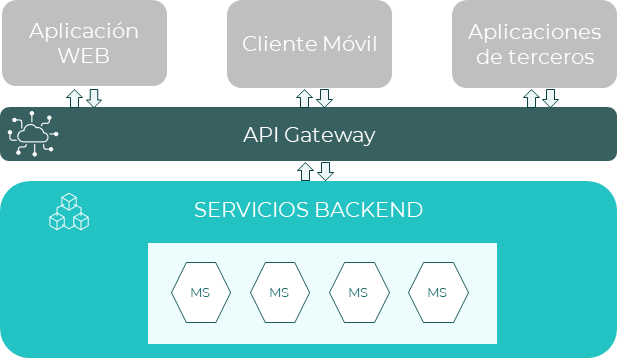
Principios que aplican:
- Desacoplamiento de componentes
- API First & Open API
- Orientado a servicios
Referencia:
Backend For Frontends (BFF)
El patrón Backend For Frontends (BFF) es una especialización del patrón API Gateway donde se genera una API de experiencia por cada canal dedicado o cliente. De esta forma, cada canal tiene una API especializada con las adaptaciones y agregaciones de información necesarias para cada uno de los canales: web, movil, internet, etc.
Las aplicaciones clientes, por tanto, solo deben interactuar con una única API en lugar de con todos los microservicios existentes de negocio, además estando las peticiones y respuestas optimizadas para las aplicaciones frontend específicas.
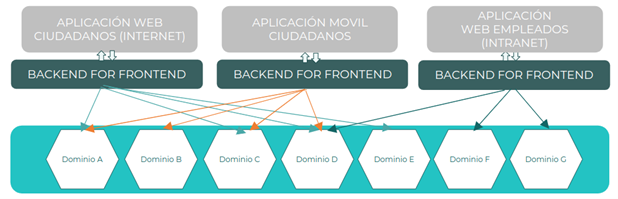
Este patrón guarda ciertas similitudes con el enfoque API-led connectivity; una forma de conectar datos con aplicaciones a través de API reutilizables y funcionalmente completas que se organizan en una arquitectura de tres capas (experiencia, procesos y sistema).
Principios que aplican:
- Desacoplamiento de componentes
- API First & Open API
- Orientado a servicios
Referencia:
Patrones de observabilidad
Application metrics
Las métricas permiten analizar si el funcionamiento de una API es correcto. Este patrón instrumenta un servicio que se encarga de enviar las métricas generadas por la API al colector de métricas para su análisis
Principios que aplican:
- Desacoplamiento de componentes
- API First & Open API
- Orientado a servicios
Referencia:
Audit logging
Este patrón permite seguir el recorrido de una petición a través de todos los servicios por los que pasa, permitiendo ver los servicios internos y externos con los que la petición ha interaccionado.
Principios que aplican:
- Desacoplamiento de componentes
- API First & Open API
- Orientado a servicios
Referencia:
Distributed tracing
El propósito de este patrón es recoger las acciones de los usuarios. Un log de auditoría se usa para ayudar a los responsables de calidad a seguir el funcionamiento de lo que ocurre en el API Manager y detectar un comportamiento sospechoso.
Cada log identifica al usuario, la acción que está realizando y el objeto de negocio.
Principios que aplican:
- Desacoplamiento de componentes
- API First & Open API
- Orientado a servicios
Referencia:
Log aggregation
Este patrón recoge los logs distribuidos en diferentes APIs y los muestra unificados para facilitar el seguimiento y el mantenimiento de las aplicaciones.
Principios que aplican:
- Desacoplamiento de componentes
- API First & Open API
- Orientado a servicios
Referencia:
Patrones de seguridad
Access token
Este patrón centraliza la entrada de peticiones en el API Gateway, que se encarga de validar la autenticación y enviarlas a otros servicios, que a su vez podrían invocar a otros servicios.
El funcionamiento de este patrón es el siguiente:
- Un servicio externo quiere hacer una solicitud a un servicio de la ADA. Para ello, según indique la arquitectura de referencia de seguridad, habrá realizado una autenticación previa.
- El API Gateway recoge la petición, analiza las credenciales y comprueba que el usuario tiene permisos para acceder a la URL que solicita. Cuando verifica que todo está correcto y que el usuario puede acceder, pasa un token de acceso que identifica de forma segura al usuario que quiere acceder.
- El servicio que recibe este token de acceso, puedo incluirlo para hacer peticiones a otros servicios.
Como puede verse, de esta forma la seguridad se gestiona de forma centralizada, pero dejando en última instancia a los microservicio capacidad para saber quién accede a sus datos y poder internamente, si es necesario, cortarles el acceso.
Principios que aplican:
- Calidad del servicio
- Zero Trust
Referencia:
Pila tecnológica
A continuación, se muestra un diagrama y se resume la pila tecnológica que se usará como solución a los componentes necesarios para la arquitectura de referencia de APIs.
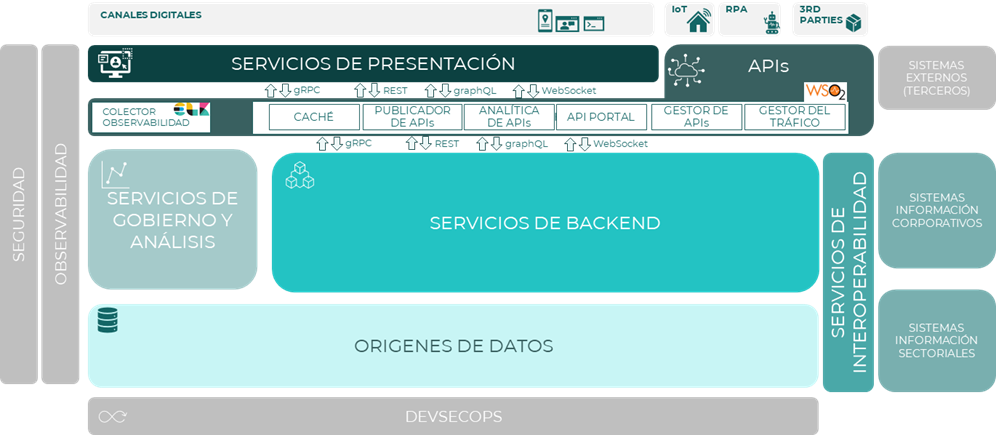
| Componente | Solución | Descripción |
|---|---|---|
| Gestor de APIs | WSO2 API Manager | WSO2 API Manager es una plataforma completa para crear, integrar y exponer sus servicios digitales como APIs administradas en la nube, on-premises y arquitecturas híbridas para impulsar su estrategia de transformación digital. |
| Publicador de APIs | WSO2 API Publisher | El API Publisher de WSO2 API Manager es una herramienta para el desarrollo y la gestión de API. Permite que los creadores de API desarrollen, documenten, protejan, prueben y versionen las API con facilidad. También es capaz de atender más tareas relacionadas con la administración de API, como publicar, monetizar y aplicar políticas de limitación de velocidad. |
| Analítica de APIs | WSO2 API Analytics | El API Analytics de WSO2 API Manager proporciona la supervisión y el análisis de las API implementadas en WSO2 API Manager. Este componente incluye diferentes tipos de paneles para proporcionar diferentes vistas estadísticas más detalladas de sus API. Además, permite proteger el sistema configurando alertas y notificaciones sobre eventos predeterminados para identificar cualquier comportamiento inusual casi en tiempo real. |
| Gestor del tráfico | WSO2 Traffic Manager | El WSO2 Traffic Manager ayuda a los usuarios a regular el tráfico de API, hacer que las API y las aplicaciones estén disponibles para los consumidores en diferentes niveles de servicio y proteger las API contra ataques de seguridad. Traffic Manager presenta un motor de limitación dinámica para procesar políticas de limitación en tiempo real, incluida la limitación de la velocidad de las solicitudes de API. |
| API Portal | WSO2 API Portal | El WSO2 API Portal es una interfaz web de última generación que permite a los editores de API alojar y anunciar sus API y, al mismo tiempo, permite a los consumidores de API registrarse, descubrir, evaluar, suscribirse y consumir API de forma segura y sencilla. |
| Caché | WSO2 API Manager WSO2 API Portal WSO2 API Publisher | Todas estas soluciones implementan la posibilidad de la habilitación de caché, ya sea para validar tokens, reducir el tiempo de carga de las páginas webs o reducir el número de peticiones a los backends. |
| Colector de observabilidad | ELK | Componente que permite gestionar la observabilidad. Se utilizará el stack ELK con Elastic, Logstash y Kibana. |
Escenarios de aplicación
A continuación, se presentan algunos escenarios donde tienen cabida la arquitectura de APIs explicada en este documento.
Publicación de APIs para aplicaciones de ciudadanos
Escenario
El primer escenario que se expone es la necesidad en la que una aplicación requiera comunicarse con un servicio de backend de nuestra organización para obtener unos datos concretos.
“El cliente X está desarrollando una aplicación web y móvil conectada con sistemas de nuestra organización y, tras autenticarse un usuario en ella, desean mostrar los datos personales del usuario que nuestra organización tiene almacenados.”
Descripción
Lo primero que necesitamos ver es en qué recursos se encuentran los datos personales necesitados para ver si hay que crear una o varias APIs. Imaginemos que los datos básicos (nombre, apellidos, nif) se encuentran en un LDAP y en una base de datos, a partir de un identificador obtenido de ese LDAP, tenemos el resto de datos demográficos (fecha nacimiento, sexo, dirección, teléfono, …).
Según estas características, construiríamos dos API REST; una primera para consultar los datos básicos del usuario a partir del nombre de usuario (por ejemplo) y otro para, a partir del identificador de LDAP, consultar el resto de datos demográficos.
A la primera API podríamos nombrarla como /usuarios/{login}
A la segunda API podríamos nombrarla como /usuarios/{id}/demográficos.
A continuación, tendríamos que definir la estructura de la respuesta que se va a proporcionar para cada una de las dos APIs.
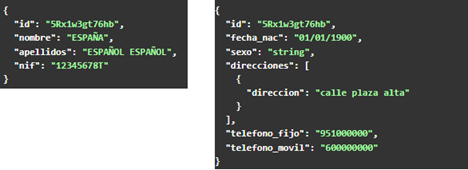
Con estos datos, ya podríamos acceder al API Manager y crear las estructuras de las APIs, documentarlas de forma correcta y crear mocks de respuestas para que el cliente pudiese comenzar sus desarrollos. Con qué sistemas se comuniquen las APIs o de qué forma, es totalmente transparente para el cliente que va a consumirlas. Solo necesita saber qué tiene que enviar y qué recibirá.
Por otro lado, aunque los canales de acceso son variados (web y aplicación móvil), recibirán los mismos datos en la respuesta por lo que no es necesario que se haga distinción para saber qué tipo de cliente es el que realiza la consulta.
Patrones
Publicación de APIs para la obtención de datos filtrados y sesgados
Escenario
El segundo escenario que se expone es la necesidad de obtención de datos almacenados en nuestra organización de forma que el cliente tenga la opción de filtrar los datos a obtener así como sesgar qué datos son los que realmente necesita que el servidor le proporcione.
“Nuestra organización tiene una serie de tablas de base de datos relacionadas y necesita exponer dichos datos para que usuarios terceros accedan a ellos. No todos van a necesitar que se les envíen los mismos datos en la respuesta y hay que dotarlos de capacidad para hacer un filtrado”.
Descripción
La problemática que presenta este escenario está en tres puntos:
- No todos los datos disponibles les son útiles a todos los clientes que van a consumir el API, quizás un cliente necesita todos los datos (por ejemplo 100 campos) y otro cliente sólo necesita un subconjunto de ellos (por ejemplo 10 campos).
- Los clientes que consuman el API deben tener la posibilidad de realizar filtrados por una serie de campos o por cualquier de los campos disponibles (esos 100 campos anteriores)
- Además, debido al tamaño de la consulta, se añade la necesidad de configurar un circuit breaker para responder un error de forma rápida si el backend está dando fallos y no seguir sobrecargándolo, permitiendo que se pueda recuperar más rápidamente.
Si hiciésemos una implementación con un API REST, como en el escenario 1, deberíamos de crear un API que en su cuerpo tuviera que pasar por qué campos filtrar, y el filtro, y qué campos requiere obtener y que el servicio backend fuese capaz de orquestar todo esto. Teniendo en cuenta que, probablemente, estos datos puedan proceder de N tablas o recursos, esta solución no cuadra con el protocolo API REST ni con los principios de la arquitectura de APIs. Otra opción sería exponer tantas APIs como recursos se vayan a consultar y eso implicaría que el cliente tenga que hacer N llamadas para obtener todos los datos, con todas las implicaciones que ello tiene.
Para dar una solución coherente a este escenario con la arquitectura explicada, lo idóneo es exponer una API con GraphQL, ya que permite al cliente, a partir de un único endpoint, indicar qué datos quiere recuperar exactamente y qué datos quiere usar como filtro. De esta forma, y similar al escenario anterior, sólo es necesario nombrar el endpoint del API y documentar muy bien la estructura de datos existente para que el cliente indique en el cuerpo de la petición, cuáles son los que necesita.
Haciendo un símil con el escenario anterior, podríamos querer consultar sólo el teléfono móvil y el nif; por lo que en el cuerpo de la petición podríamos indicar lo siguiente:
{
usuario {
telefono_movil
nif
}
}Lo que haría que sólo se devolvieran esos dos campos y no todos los demás. Por ejemplo, en un escenario tipo sanitario podríamos encontrarnos con pacientes, citas, informes, profesionales, unidades, centros de atención, vacunas, … pudiéndose hacer las relaciones tan grandes como queramos. Haciendo uso del protocolo REST como en el escenario 1, habría que crear infinidad de APIs para dar servicio a todos o una API que devolviese toda la información, con los problemas que ello implica a nivel de comunicaciones de red.
Patrones
Publicación de un API de una respuesta en función del cliente usado por el usuario
Escenario
El tercer escenario que se expone soluciona la necesidad de publicar un API que pueda responder con unos datos concretos en función del cliente (web, móvil) usado para realizar la petición.
“Se va a realizar una aplicación con cliente web y móvil que, en función de la pantalla o menú en el que se encuentre el usuario, tendrá que mostrar unos datos. Aunque guardan cierta relación, la cantidad de datos mostrados difieren entre clientes, mostrando más datos en una pantalla web que en la misma opción de menú de móvil. Además, la aplicación web contendrá un buscador avanzado de datos y podrá indicar los campos a recuperar de esa búsqueda mientras que el cliente web tendrá sólo ciertas opciones controladas de filtrado y siempre recibirá los mismos campos”.
Descripción
En primer lugar, separamos las problemáticas del escenario y luego abordaremos la solución:
- Según el cliente, el conjunto de datos a recibir ante una misma petición, pueden diferir
- El cliente web tendrá opciones de búsqueda más amplias que el cliente móvil
Al escenario expuesto, por principios de arquitectura de APIS, hay que añadir que el tiempo de respuesta en cliente móvil no se puede ver perjudicado por el exceso de datos transmitidos y que el número de peticiones por unidad de tiempo que se puede soportar desde cliente móvil no se puede ver perjudicado por la web.
Para dar solución a este escenario, publicaremos APIs REST para la obtención de datos en general (como se hizo en el primer escenario) y APIs GraphQL para la búsqueda avanzada desde web (como se hizo en el segundo escenario).
Surge el problema de ¿cómo hacer que a una petición enviada desde cliente web se le responda con una serie de datos y a la misma petición realizada desde un cliente móvil, en cambio, se le responda con parte de esos datos? ¿Y qué pasa si hay que hacer algún cambio en el futuro?
La solución está en el patrón backend for frontend. Este patrón permitirá generar un punto de entrada único para cada cliente. Esto significa que cada tipo de cliente accede a una API exclusiva que soporta sus casos de uso, es decir, al cliente móvil no le va a llegar un exceso de datos innecesario ni al cliente web le van a llegar menos datos de los que necesita.
De esta forma, se simplifica el acoplamiento entre las aplicaciones y los servicios backend. Además, si el servicio evoluciona y aparecen nuevos campos o se eliminan algunos, sólo hay que retocar el canal que se vea afectado.
Patrones
Referencias
- Referencias técnicas: