Información general

Diagrama de despliegue
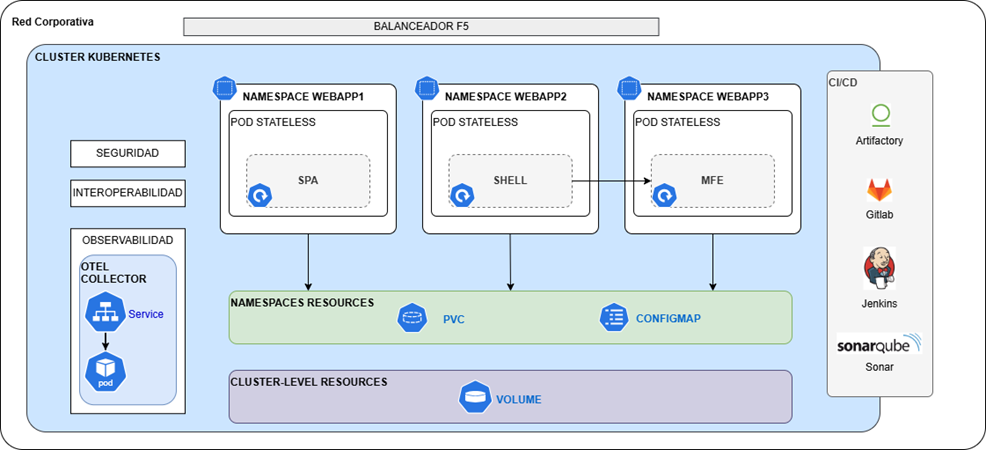
Namespace
Existirán namespaces propios para las aplicaciones web que se organizarán en función de los proyectos o iniciativas registradas por los distintos organismos.
En cada uno de los namespaces se realizará el despliegue de las aplicaciones web que estén asociados al proyecto o iniciativa.
Para tener un namespace operativo en Openshift deberán seguirse los siguientes pasos:
- Debe solicitarse la creación del namespace al equipo de operaciones mediante una solicitud.
- Al hacer la petición debe indicarse el nombre del namespace. El nombre debe coincidir con el nombre del proyecto en git añadiéndole un prefijo que indicará el entorno. Se recomienda consultar la normativa sobre nomenclatura de proyectos en git para evitar problemas durante el despliegue de los microservicios que se encuentren dentro del proyecto git.
Por ejemplo: Si en git tenemos si-proyecto, en openshift deberemos solicitar la creación de los namespaces des-si-proyecto, pru-si-proyecto y pro-si-proyecto.
- Cuando el namespace esté creado se debe abrir una petición a devops para que el equipo deje el namespace preparado para poder iniciar despliegues.
Imagen de la aplicación web
Cada aplicación web se empaquetará en una imagen y se ejecutará como un contenedor dentro de un pod. La imagen base que utilizarán las aplicaciones web será proporcionada por el Área de Infraestructura y deberá formar parte del catálogo de imágenes base.
La imagen base para las aplicaciones web está basada en node 22 y utiliza nginx como servidor de aplicaciones.
El gobierno de la imagen base corresponde al área de Infraestructura, siendo responsabilidad de ellos detectar problemas de seguridad y actualizarlas cuando sea necesario.
Cuando una imagen base se actualiza, los equipos de desarrollo serán los responsables de programar y ejecutar el despliegue de las aplicaciones web que utilizan esa imagen base para garantizar que el producto en los entornos no productivos está actualizado. En producción, el equipo de desarrollo será el encargado de solicitar un despliegue de esas aplicaciones web abriendo las peticiones necesarias y siguiendo el protocolo establecido.
Para los proyectos legacy que no dispongan de un equipo de mantenimiento, deberá nombrarse un responsable para ejecutar una actualización de la imagen base cuando sea necesario.
Todas las aplicaciones web contendrán un fichero .dockerfile cuya imagen base será la proporcionada por el área de Infraestructura. Este fichero .dockerfile debe estar en la carpeta raíz de la aplicaciones web y será responsabilidad de los equipos de desarrollo incorporarlo y mantenerlo.
Para simplificar el gobierno del fichero .dockerfile, el activo ada-fwk-webapps proporcionará a las aplicaciones web que lo incorporen un fichero .dockerfile por defecto en los arquetipos SPA y Shell + MFE que el activo publica para simplificar la creación de aplicaciones web.
Pod
Los pods son objetos que representan la unidad básica de despliegue en Kubernetes. Internamente un pod puede estar compuesto de uno o más contenedores.
La lógica de una aplicación web se almacena en un único pod. De un pod pueden crearse varias réplicas que permiten distribuir la carga y garantizar la alta disponibilidad. Durante el despliegue del pod debe definirse qué contenedores lo conforman, así como la configuración de estos.
En concreto, las aplicaciones web se desplegarán como pods en los que para cada entorno se establece un número mínimo de réplicas:
| Entorno | Número de réplicas |
| Test | 1 |
| Preproducción | 3 (Alta disponibilidad) |
| Preproducción | 3 (Alta disponibilidad) |
Para garantizar la alta disponibilidad se deberá verificar que existen definidos Placement Rules que distribuyan las diferentes réplicas entre todos los cluster disponibles. De esta forma, aunque algún nodo del cluster tenga alguna incidencia, siempre existirán réplicas de las aplicaciones web corriendo en otros nodos.
Para ello deberán existir una serie de recursos y configuraciones para cumplir la alta disponibilidad de las aplicaciones:
- HorizontalPodAutoscaler: Este recurso ajusta automáticamente el número de réplicas de un pod en función de la utilización observada de CPU/memoria o de otras métricas seleccionadas. El propósito principal del HPA es asegurar que las aplicaciones puedan manejar cambios en la carga de trabajo sin intervención manual, mejorando así la resiliencia y la eficiencia de los recursos.
- Pod anti-affinity: Este recurso va a permitir que las réplicas de cada pod se desplieguen en diferentes nodos asegurando disponibilidad de la aplicación en caso de caída de uno de los nodos donde se encontrara una de las réplicas del pod aplicativo.
El arquetipo proporciona una configuración estándar sobre los recursos con los que va a contar el pod donde se despliega una aplicación web. Es responsabilidad del equipo de desarrollo identificar si la aplicación web va a necesitar una mayor cantidad de recursos y solicitarlo.
Despliegue de aplicaciones web
Las aplicaciones web se desplegaran en pods sin estado o stateless, que son aquellos que no guardan el estado de la aplicación que contienen, es decir, no guardan datos que necesiten ser conservados tras la eliminación o el reinicio del pod.
Este tipo de despliegue permite gestionar las réplicas de un pod de forma dinámica. A la hora de definir un deployment deben configurarse:
- Los contenedores que componen el pod.
- El dimensionamiento de los pods y el número de réplicas.
- Las reglas para automatizar el escalado en base a los picos y valle de uso.
- Mecanismos de rollback automatizados para restaurar el servicio en el caso de que el despliegue falle.
Se deberá generar un recurso de tipo Deployment; el equipo de desarrollo será el responsable de su creación, mantenimiento y almacenado en el repositorio del aplicativo. De cara al despliegue del aplicativo no se deberá realizar ningún cambio adicional.
Servicio
Un Servicio es un recurso de la plataforma que proporciona un punto de acceso estable a una aplicación ejecutándose en un conjunto de pods como un servicio de red. La creación de los servicios se hará mediante el objeto de Kubernetes y con la ayuda de la herramienta que Openshift dispone para facilitar el descubrimiento y acceso a estos servicios.
Todos los servicios existentes en el namespace estarán definidos con un DNS y tendrán un puerto asociado. De esta forma, durante el arranque del microservicio se establecerá una conexión con el servicio de auto-descubrimiento de openshift que permitirá mapear los DNS por IP válidas para establecer la comunicación.
El principal beneficio de usar servicios y el servicio de auto-descubrimiento proporcionado por Openshift es que abstrae a los microservicios de conocer la url física de los componentes con los que se quiere comunicar. Dado que la IP se renueva cada vez que se reinicia el pod y que nunca se conocen cuantas réplicas tiene activo un microservicio, es muy complicado conocer esa información. Gracias al servicio de auto-descubrimiento este proceso es transparente para el microservicio que solo se tiene que preocupar por conocer el DNS y el puerto del servicio con el que se quiere comunicar.
Se publicará como servicio cualquier api que deba ser invocada por otros microservicios o componentes software dentro o fuera del namespace.
El nombrado del servicio se basa en la norma establecida para el nombrado de componentes añadiendo el sufijo -svc.: [S/SA/SI]-[sistema]-[componente]-svc.
En los entornos de desarrollo los equipos serán los responsables de crear y configurar los servicios que requieran los microservicios para su correcto funcionamiento. En producción deberá abrirse una petición a operaciones solicitando la creación o modificación del servicio.
Persistent Volume Claim
Un Persistent VolumeClaim es un objeto en Kubernetes que permite solicitar y reservar un recurso de almacenamiento persistente. Permite a los pods de las aplicaciones web acceder al almacenamiento persistente sin importar el proveedor o la tecnología subyacente.
Un Persistent Volume Claim siempre está asociado a un volumen. Cuando la vinculación con el volumen se realiza con éxito, el pod puede utilizar ese volumen como almacenamiento persistente. Se encarga de administrar el ciclo de vida del recurso de almacenamiento, lo que incluye la creación, el montaje y la liberación del almacenamiento cuando ya no es necesario.
Solicitud de creación de PVCs para los distintos entornos
Crear una petición desde la tarea de Aprovisionamiento de entornos con los siguientes datos:
- Asunto: Solicitud de creación de PVC - [nombre_del_pvc] en [nombre_del_namespace] - [DES/PRE/PRO]
- Contenido del tique:
- Nombre del PVC: Nombre único para el PVC dentro del namespace.
- Namespace: Namespace donde se debe crear el PVC.
- Tamaño del almacenamiento: Especificad el tamaño en las correspondientes unidades. Por ejemplo: 1Gi.
- Modo de acceso:
- ReadWriteOnce (RWO)
- ReadOnlyMany (ROX)
- ReadWriteMany (RWX)
- Descripción del uso: Breve explicación del propósito del PVC.
Asignar el tique al equipo de operaciones: Derivad el tique al grupo "Cloud-Ops-PEC".
Será necesario subir al repositorio el archivo manifest.yaml donde se defina este PVC, para seguir y cumplir el modelo GitOps.
Para la aplicación del recurso PVC en la plataforma se deberá crear un tique dirigido al equipo de operaciones donde se deberán adjuntar el manifiesto a aplicar o en su defecto incluir la url del repositorio donde se encuentre almacenado.
Volumen
Un volumen es un objeto de Kubernetes que permite almacenar información de forma persistente. En un objeto de tipo Volumen se almacena aquella información que no quiere perderse cuando el pod desaparezca.
Un pod puede tener asociado ninguno, uno o varios volúmenes. Los volúmenes son unidades de almacenamiento independientes para cada pod aunque compartida por todos los contenedores que lo forman.
Es posible crear volúmenes que se compartan entre varios pods usando el objeto de Kubernetes PersistentVolumeClaim.
Configuración
Los arquetipos de las aplicaciones web proporcionan un fichero de configuración que se carga al inicio de la aplicación y que es configurable por entorno. Este fichero de configuración se configura mediante ficheros ConfigMap. Estos ficheros almacenan propiedades de configuración específicas de las aplicaciones web. Este fichero es único en cada entorno y su gobierno es responsabilidad del equipo de desarrollo.
La pipeline de despliegue de las aplicaciones web creará el configmap y lo utilizará para crear el fichero de configuración que se almacena en la carpeta /config dentro del directorio de nginx.
En el entorno de desarrollo será responsabilidad de los equipos verificar y comprobar que este fichero se ha creado correctamente cuando ejecuten la pipeline de despliegue. En el entorno de producción deberán establecer mecanismos con el equipo de operaciones para verificar el contenido de dicho fichero y garantizar que el despliegue se ha realizado correctamente.
OTEL Collector
El OTEL Collector es un componente basado en Open Telemetry cuya principal funcionalidad es recopilar y procesar la información de observabilidad recolectada por cada uno de los componentes desplegados en el namespace. La información recogida se mandará a los componentes de la Plataforma de Observabilidad para su gestión y visualización.
El principal beneficio de Open Telemetry Collector es que permite aislar a las aplicaciones web y resto de componentes de la Plataforma de Observabilidad. Una aplicación web no necesita saber a dónde van a dirigirse las métricas, trazas y logs generados; Open Telemetry Collector centraliza la recolección y manda la información a los diferentes destinos que tiene configurado.
Estos destinos pueden ser las herramientas de observabilidad (Prometheus, Grafana, Jaeger…) definidas en la Plataforma de Observabilidad centralizada o específicas para un namespace concreto. Para las aplicaciones web este proceso no es relevante lo que permite aislarlos simplificando su codificación.
Una aplicación web utiliza el agente de OpenTelemetry para enviar al OTEL Collector las métricas, trazas y logs producidas por el código en tiempo de ejecución. Estas métricas, trazas y logs incluyen tanto las que genera automáticamente el framework bajo el que se esté desarrollando, las librerías de tercero que el microservicio incorpore y las generadas programáticamente por el equipo de desarrollo directamente en el microservicio.
Se deja abierta la posibilidad de que si un proyecto necesita un procesamiento personalizado de sus métricas, trazas y logs puedan instalarse en su namespace su propia instalación del componente OTEL Collector. En desarrollo el equipo será el responsable de instalar y mantener este componente. En producción, deberá mantenerlo el equipo de operaciones por lo que previamente deberá solicitarse la autorización del equipo de operaciones antes de realizar esta personalización.
No se usará OTEL Collector para la gestión de las métricas, trazas y logs generadas por el pod a bajo nivel que serán procesadas y enviadas a los servicios de tercero mediante otros mecanismos. Concretamente, para el caso de la recolección de logs de los pods aplicativos, existen pods collectors en cada nodo encargados de recoger y procesar todos los logs de cada pod mostrados por la console output para después ser indexados por la herramienta ElasticSearch. Desde Kibana se podrán visualizar todos los logs de la plataforma, así como crear gráficos y dashboards en caso necesario. Por otro lado, existen unos pods exporter en cada nodo que serán los encargados de recoger todas las métricas de cpu, memoria, i/o, networking, etc y enviarlos a Prometheus para su almacenado. Grafana será la herramienta para la visualización de estas métricas mediante el uso de los dashboards generados por defecto. En caso de que se precise la creación de métricas personalizadas se deberá solicitar la creación de un Grafana (tiene que ser el operador de Grafana de la versión Community) para albergar estas métricas y posibilitar la creación de dashboards personalizados.
Comunicaciones
A continuación, se indican los diferentes casos de uso que se identifican para gobernar la comunicación de las aplicaciones web con otros servicios.
Comunicación entre una aplicación web y un servicio de interoperabilidad
Este tipo de comunicación normalmente se produce cuando una aplicación web solicita información a un componente Backend de un Servicio de Información Corporativo o un Sistema de Información Sectorial para realizar una tarea.
Deberá analizarse, por parte del equipo de desarrollo, qué información debe solicitar la aplicación web para que el equipo de la Oficina de Interoperabilidad cree las API necesarias, siguiendo los criterios establecidos por la Arquitectura de API, desplegándolas en el API Manager siguiendo las directrices indicadas en el Modelo de Despliegue de API.
La comunicación entre el Frontend y el Backend siempre tiene que estar securizada mediante token JWT, mTLS o algún mecanismo de seguridad similar que garantice que se cumple el principio de Zero Trust, y aunque API Manager haga una comprobación de seguridad el microservicio deberá también hacer sus propios controles.
Proceso de Despliegue
Entorno pre-cloud
Prerrequisitos que deben cumplirse antes de iniciar el proceso de despliegue:
- En el entorno donde se va a desplegar, el proyecto debe tener un namespace de Openshift asignado. El nombre de este namespace debe cumplir los requisitos de nomenclatura. Si no existe este namespace debe solicitarse su creación.
- La aplicación web que se va a desplegar tiene que tener asociado un proyecto en Git. El nombre de este proyecto debe cumplir los requisitos de nomenclatura y todo el repositorio tiene que seguir los criterios establecidos por la estrategia de ramificación.
A continuación se listan los pasos para desplegar una aplicación web.
- Contactar con DevSecOps para notificar el despliegue de la aplicación web y solicitarles los siguientes elementos:
- Creación de una instancia de la pipeline de camino único en Jenkins.
- Creación del despliegue en ArgoCD.
- Crear el webhook en el repositorio git, con los siguientes datos:
- URL: Instancia de la pipeline proporcionada por DevSecOps
- Marcar estos checks: Tag push events, Merge request events y Enable SSL verification.
- La aplicación web debe contar con una configuración básica. Cuando se utilicen los arquetipos SPA o Shell + MFE del framework ada-fwk-webapps, se generará automáticamente una aplicación web con los ficheros obligatorios y una configuración por defecto. Esta configuración deberá ser revisada y ajustada por el equipo de desarrollo según las necesidades del proyecto:
- Fichero dockerfile: Contiene la imagen base para el despliegue de la aplicación web y cualquier otro elemento necesario para la generación de la imagen.
- Fichero ci.json: Contiene la configuración de los parámetros de entrada para la correcta ejecución de la pipeline de Jenkins.
- Fichero sonar.properties: Contiene la configuración para que la pipeline pueda ejecutar correctamente el paso de validación de calidad del código en Sonarcube.
- Directorio despliegue: Este directorio contiene una carpeta para cada entorno (test, pre y pro). Cada carpeta contiene los ficheros necesarios para el despliegue en ese entorno. El contenido de esta carpeta sigue el patrón de despliegue de Kubernetes Kustomize.
- Iniciar el proceso de despliegue siguiendo el procedimiento indicado en la documentación relativa a la estrategia de ramificación y verificar tanto en Jenkins como en ArgoCD y Openshift que el proceso de despliegue se está ejecutando correctamente.
Para más información sobre estos ficheros consultar la documentación publicada por DevSecOps y la documentación oficial de Red Hat Openshift y Kubernetes.